What Makes a Scalable Multiplayer Game Architecture Work
There is a moment every multiplayer game studio dreads. The game launches. Social media picks it up. A streamer with two million followers goes live. Within forty minutes, the servers are on fire, matchmaking queues stretch to eight minutes, and players are dropping out faster than they joined. The game itself is great. The architecture behind it was not ready.
This is not a rare story. It happens to well-funded studios with experienced teams because scalable multiplayer game architecture is genuinely hard to get right, and the decisions that break you at scale are usually made in the first two months of development when everything still feels manageable.
This post breaks down what actually makes a multiplayer backend hold together under real production conditions, where the common failure points are, and how studios can build or commission infrastructure that does not become a liability the moment it succeeds.
Why Game Server Architecture Is the Foundation Most Studios Under-Engineer
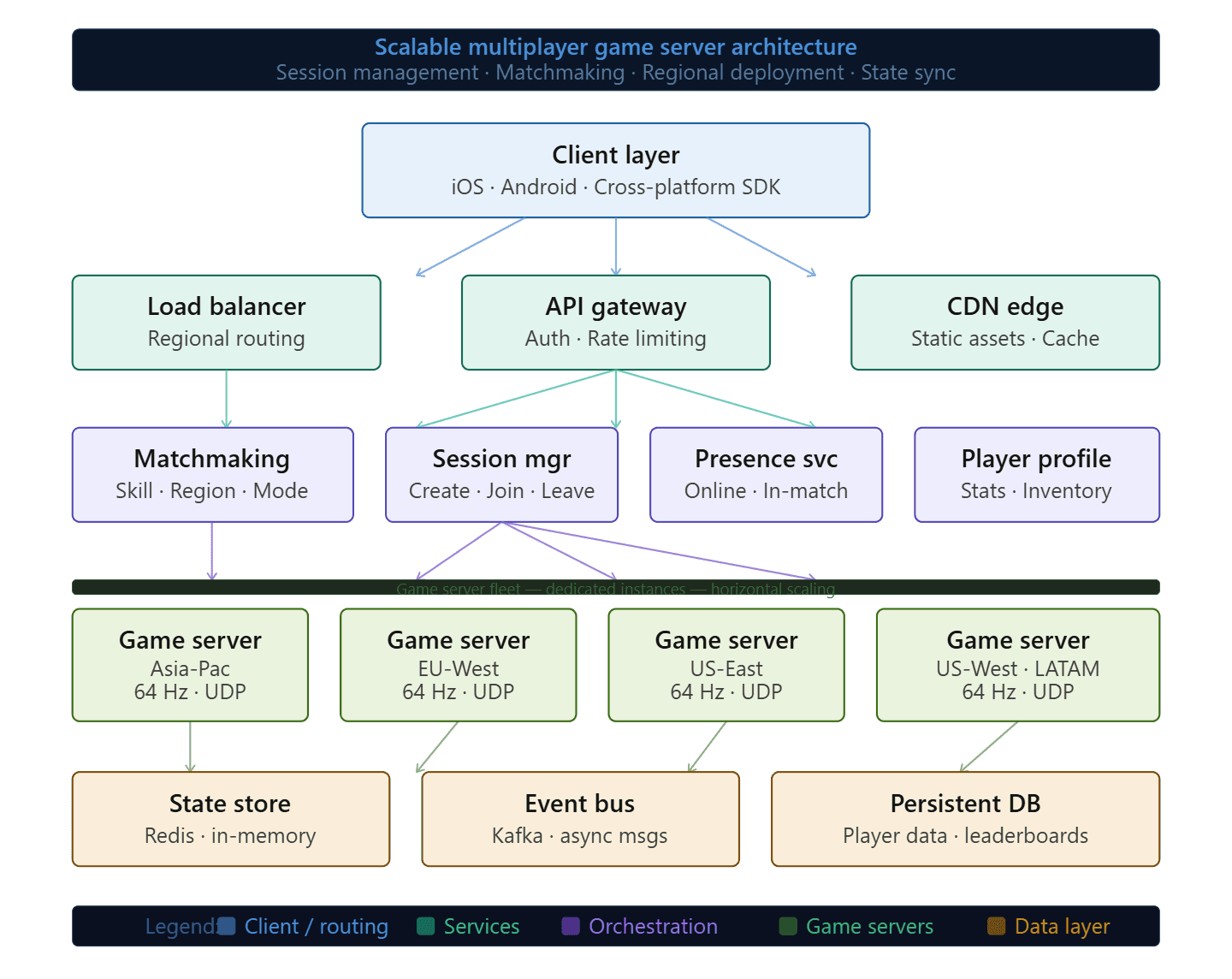
The game server is the source of truth in any multiplayer game. Every player action flows through it, every game state change originates from it, and every client in the session is constantly reconciling its local view of the world against what the server says is real.
Most studios design their early server architecture around what they need to get a prototype working, which is completely reasonable. The problem is that prototype architecture tends to stay in place longer than anyone intends. A server that was designed to handle 50 concurrent players in a single game session behaves completely differently when you need it to manage 10,000 concurrent sessions across multiple regions simultaneously.
The core mistake is treating the game server as a single unit rather than a distributed system. A single authoritative server works for development and small-scale testing. At production scale, you need session management separated from game logic, matchmaking running as its own service, and state persistence handled by something that can survive a server restart without dropping players mid-session.
The other foundational decision that studios consistently underestimate is where to run the servers. Shared cloud instances are fine for early testing. Dedicated game servers, meaning instances reserved entirely for game traffic rather than shared with other workloads, are what you need when frame-perfect consistency and predictable latency matter.
Key Takeaway: A multiplayer game backend designed for prototyping will fail at production scale. The architecture needs to treat the server as a distributed system from the start, not a single process that gets bigger over time.
Real-Time Game Networking: Tick Rate, Protocol Choice, and Why Latency Targets Are Non-Negotiable
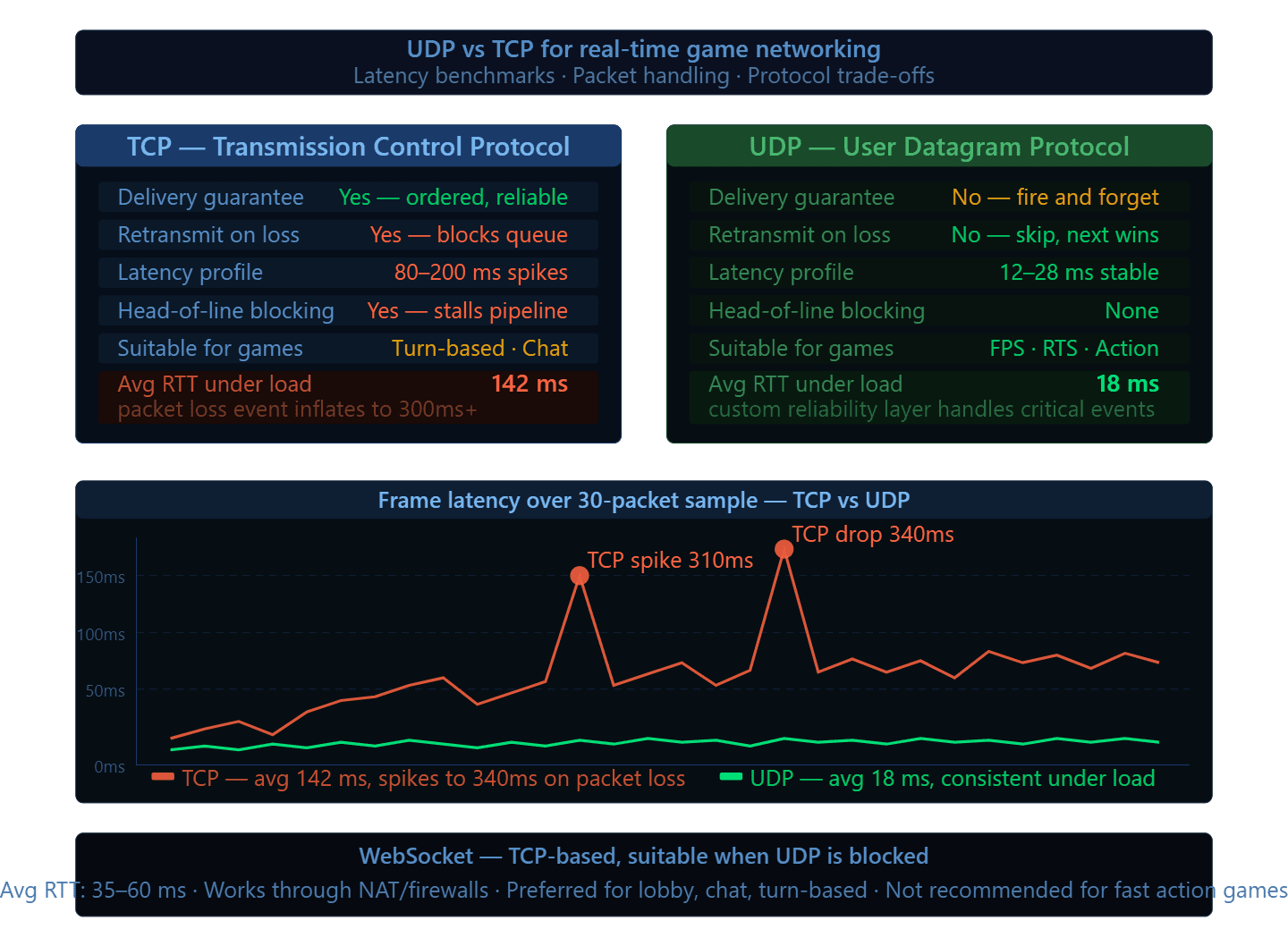
The most common number you will hear in multiplayer networking discussions is the tick rate, which is how many times per second the server processes game state and broadcasts updates to clients. A server running at 20 ticks per second sends a state update every 50 milliseconds. At 64 ticks, that drops to 15.6 milliseconds. Competitive shooters typically run between 60 and 128 ticks. Turn-based or slower-paced games can operate comfortably at 20.
Tick rate alone does not determine the player experience. Protocol choice matters just as much.
TCP guarantees packet delivery and ordering, which sounds ideal until you realize that those guarantees come with retransmission delays. In a fast-moving game, waiting for a dropped packet to be resent before processing the next one introduces latency spikes that make the game feel broken even on a good connection. UDP sends packets without delivery guarantees, which means the game logic has to handle packet loss itself, but the round-trip times are dramatically lower and more consistent. Most real-time multiplayer games use UDP with a custom reliability layer built on top for the packets that genuinely need to arrive, such as critical game events, while accepting that some position updates simply get dropped and replaced by the next one.
WebSocket is a reasonable middle ground for games where the action is less time-sensitive. It runs over TCP but adds connection management that raw TCP sockets do not provide, and it works well through firewalls and NAT environments that cause problems for raw UDP.
How Game State Synchronization Keeps Every Client in Agreement
State synchronization is the process of making sure every player's client reflects the same game world at the same moment, even though network latency means different players receive updates at slightly different times.
The two main approaches are state replication, where the server sends the full game state or a delta of changes to all clients at each tick, and event-based sync, where only specific events are broadcast and clients reconstruct state from those events. Most production multiplayer games combine both. Frequent low-importance updates like player positions use delta compression to minimize bandwidth. High-importance events like player deaths or item pickups use reliable delivery.
Client-side prediction is what makes the game feel responsive even when the server is 60 milliseconds away. The client applies the player's input locally and immediately, without waiting for server confirmation. The server then processes the same input, sends back its authoritative result, and the client reconciles any difference. If the client predicted correctly, the player sees no visual correction. If there was a mismatch, the client rolls back and re-simulates from the last confirmed server state. When implemented well, players feel zero latency on their own inputs even over a 100 millisecond connection.
Key Takeaway: Low-latency game servers require UDP networking, a tick rate matched to the game's pacing, and client-side prediction that hides network delay behind responsive local simulation.
Online Game Infrastructure: Scaling Horizontally When Your Player Count Stops Being Predictable
A game that grows means a backend that needs to scale, and scaling a multiplayer backend is fundamentally different from scaling a web application. Web servers handle stateless requests. Game servers handle persistent, stateful sessions where every player in a match is connected to the same process and that process cannot simply be swapped out mid-game.
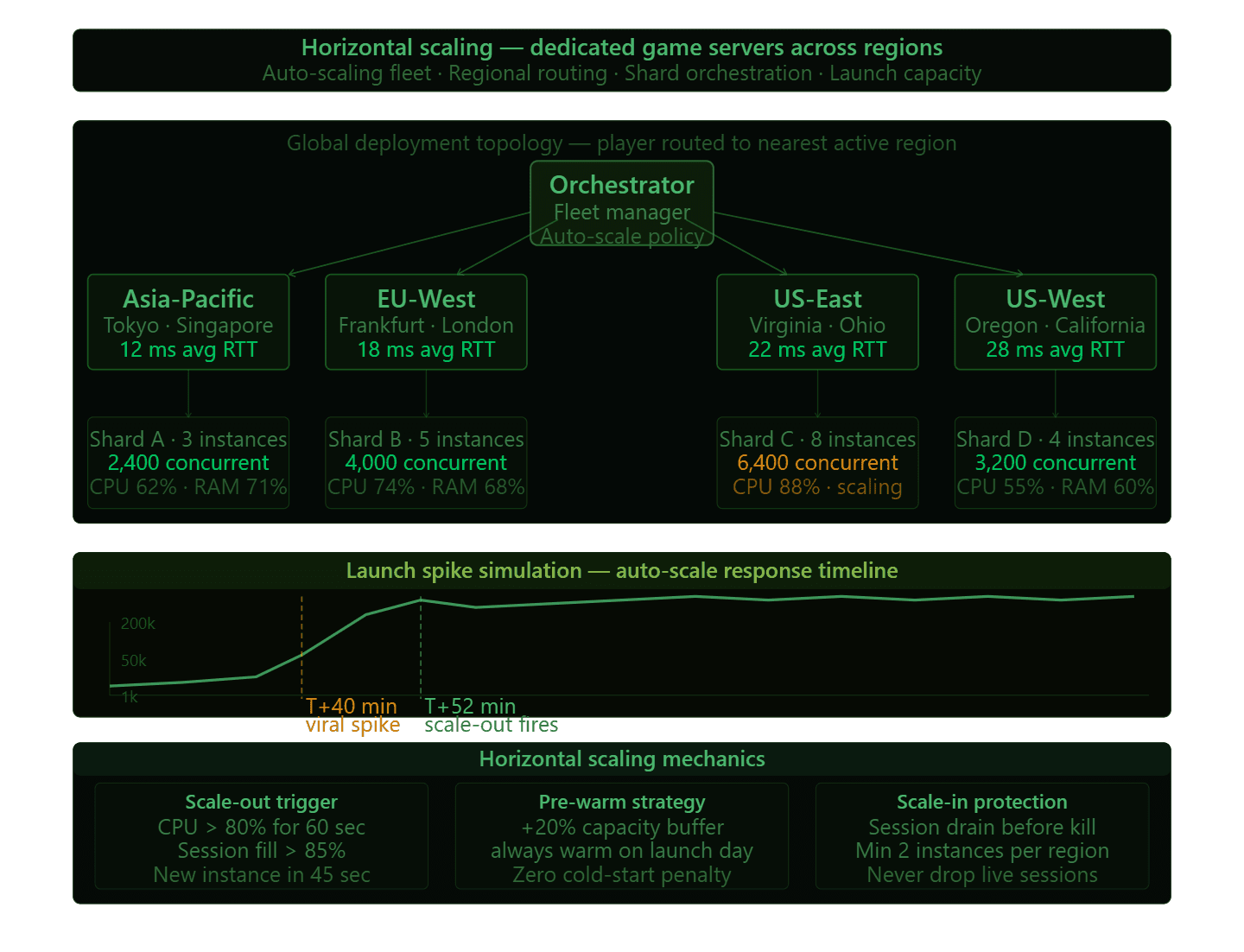
Horizontal scaling for multiplayer games means adding more server instances, not making existing ones larger. When a new match starts, it gets assigned to an available server instance in the appropriate region. When that instance is full, the orchestration layer spins up another one. The matchmaking service sits in front of all of this and handles the routing.
Sharding is how you manage this at very large scale. Rather than one massive game world that every player shares, you divide the population into independent shards, each running on its own set of servers. Players in one shard do not interact with players in another. This is standard practice for MMOs but the same principle applies to any game that needs to support hundreds of thousands of concurrent players across different game modes, regions, or match types.
Regional server deployment is not optional for a global title. A player in Mumbai connecting to a server in Frankfurt will see 150 to 200 milliseconds of latency, which is completely unacceptable for any game with real-time action. Deploying server instances in multiple geographic regions and routing players to the nearest available server is the baseline expectation. The infrastructure complexity this adds is significant, but the alternative is players in specific regions having a fundamentally worse experience than others.
Launch spikes are where a lot of infrastructure plans fall apart. A game can go from 1,000 to 200,000 concurrent players in 48 hours if it catches viral attention. Auto-scaling policies, pre-warmed server fleets, and regional capacity buffers are the engineering answers to this, but they have to be designed in before launch, not patched in during the chaos.
Key Takeaway: Scalable online game infrastructure runs on horizontal scaling, regional deployment, and pre-engineered capacity buffers. None of these can be bolted on after a viral launch.
When to Build It In-House and When to Work With a Multiplayer Game Development Partner
Studios face a real decision early in production: build the backend engineering capability internally or work with a team that already has it.
Building in-house gives you full ownership and control. It also requires hiring engineers who specialize in distributed systems, network programming, and game backend infrastructure, a combination that is genuinely rare and expensive. A mid-size studio trying to ship a game in eighteen months while also building a senior backend team from scratch is usually doing neither thing as well as it could.
The partner route works when you need depth you do not have time to build. The value is not just the code. It is the accumulated knowledge of what breaks at 10,000 concurrent players, what breaks at 500,000, and how to design systems that handle the transition between those numbers without a crisis.
P99Soft has built multiplayer backend systems across mobile and cross-platform titles, working through the practical engineering problems that show up in production rather than in controlled environments. The game development services we deliver in this space are shaped by what we have learned on shipped titles, not theoretical architecture.
The honest framing for this decision is: how central is backend engineering to your studio's core competency? If your competitive advantage is game design, art direction, and player experience, the backend is essential infrastructure but not your differentiator. Treating it that way, and staffing accordingly, is a reasonable call.
Key Takeaway: The build versus partner decision for multiplayer backend comes down to whether backend engineering is a core studio competency or essential infrastructure that another team can deliver faster and with more depth.
Multiplayer architecture is one of those areas where the cost of getting it right early is a fraction of the cost of fixing it under pressure. Studios that invest in the backend foundation before launch give themselves room to focus on what actually makes the game worth playing.
If your studio is working through these architecture decisions, P99Soft is worth talking to. The conversation tends to surface problems worth solving before they become launch-day emergencies.
FAQ
What is a scalable multiplayer game architecture?
A scalable multiplayer game architecture is a backend system designed to handle growing player counts without degrading performance or requiring a rebuild. It typically includes an authoritative game server, distributed session management, regional deployment, and horizontal scaling so that adding more players means adding more server instances rather than overloading existing ones.
What tick rate should a multiplayer game server run at?
The right tick rate depends on the game's pacing. Competitive shooters and action games typically run between 60 and 128 ticks per second, meaning the server processes and broadcasts game state up to 128 times every second. Slower-paced games can run well at 20 ticks per second. Running a tick rate higher than the game's action requires wastes server resources without improving the player experience.
Why do multiplayer games use UDP instead of TCP?
UDP is preferred in real-time multiplayer games because it does not wait for dropped packets to be resent before continuing. TCP's delivery guarantees introduce latency spikes that make fast-moving games feel unresponsive, especially over connections with any packet loss. Most multiplayer games use UDP with a custom reliability layer built on top for the small number of events that must be delivered in order.
How do you scale a game server for a large player spike at launch?
Handling a launch spike requires pre-warmed server fleets, auto-scaling policies that spin up new instances within seconds of demand increasing, and regional capacity buffers that provide headroom before demand hits the ceiling. The key is that these systems have to be designed and tested before launch. Auto-scaling configured the night before a big release is not a scaling strategy.