Service Mesh Explained: What Istio Does, Why Teams Adopt It, and When It Is Worth the Complexity

At a certain scale of microservices deployment, a specific set of problems arrives simultaneously. Every service needs to handle retries when a downstream service times out. Every service needs encrypted communication with every other service. Engineers need to trace a single user request across fifteen services to understand why it failed. And the platform team needs to shift 5% of traffic to a new service version without touching application code.
Without a service mesh, each of these problems gets solved independently, inside each service, by each development team, with varying degrees of completeness. The result is inconsistent retry logic, inconsistent encryption, inconsistent observability, and a traffic management capability that requires code changes every time it needs to be adjusted.
A service mesh solves all four problems at the infrastructure level, once, for every service in the cluster simultaneously.
CNCF's Annual Cloud Native Survey found that innovators are nearly three times more likely than explorers to run a service mesh in production, signaling that maturity in cloud native practices correlates with advanced traffic management and security adoption.
Istio graduated from the Cloud Native Computing Foundation in July 2023 and has since become the most widely deployed service mesh in production Kubernetes environments. Since its CNCF graduation, Istio has promoted ambient mode to stable, making it the fastest and most efficient service mesh as well as the most widely used. Understanding what it does, why organizations adopt it, and when the operational overhead is worth accepting is the question this article answers directly.
What Is a Service Mesh and What Problem Does It Actually Solve
A service mesh is an infrastructure layer that handles service-to-service communication within a distributed system, providing traffic management, security, and observability without requiring application code changes.
In a Kubernetes environment without a service mesh, communication between services is direct and largely unmanaged at the infrastructure level. Service A calls Service B over HTTP or gRPC. If Service B is slow, Service A needs to implement its own timeout and retry logic. If the organization requires encrypted communication between services, each service needs to implement mutual TLS itself. If an engineer needs to trace a request across multiple services, each service needs to be instrumented with tracing libraries.
This per-service implementation model scales poorly. It means reliability logic is scattered across every service codebase, enforced inconsistently, and changed one service at a time. A security team that wants mutual TLS across all internal service communication in a cluster with 50 microservices needs 50 separate code changes, 50 separate deployments, and 50 separate verifications.
A service mesh functions as an infrastructure layer that equips applications with zero-trust security, observability, and advanced traffic management capabilities without requiring code modifications.
The mesh solves this by placing a proxy, in Istio's case the Envoy proxy, either alongside each service as a sidecar container or, in Istio's newer ambient mode, as a node-level component. All traffic entering and leaving each service passes through this proxy. The proxy handles encryption, retries, circuit breaking, and telemetry collection. The application code knows nothing about any of it. The operational team configures all of it centrally through Istio's control plane.
A service mesh does not make your application code more reliable. It makes the infrastructure that your application code runs on more secure, more observable, and more controllable without asking development teams to add that capability to every service individually.
What Istio Actually Does: Four Capabilities Explained
Istio provides four distinct capabilities that together make it worth the operational investment for engineering organizations running microservices at sufficient scale. Understanding each one separately helps clarify where the value comes from and which problems Istio solves versus which ones it does not.
Mutual TLS between every service automatically. Mutual TLS, abbreviated mTLS, is a security protocol where both the client and the server authenticate each other's identity before exchanging any data. In a non-mesh environment, internal service communication typically happens over plain HTTP or unverified HTTPS. A compromised service can call any other service it can reach on the network without presenting credentials.
Istio enforces mTLS between every service pair in the mesh automatically. Services receive certificates from Istio's certificate authority. Every connection between services is encrypted and authenticated. A compromised service cannot impersonate another service or intercept traffic between services it has no legitimate reason to communicate with. This zero-trust networking model, where no service is trusted by default regardless of where it runs in the cluster, is one of the primary adoption drivers for regulated industries.
Traffic management without application code changes. Istio allows platform and SRE teams to control exactly how traffic flows between services through configuration rather than code. Canary deployments, where a percentage of traffic routes to a new service version while the remainder stays on the current version, require no application changes. A canary that starts at 1% of traffic and expands gradually based on error rates is configured entirely through Istio VirtualService and DestinationRule resources.
Circuit breaking, the pattern where a service stops sending traffic to a downstream dependency that is failing rather than waiting for each request to time out, is configured at the mesh level rather than implemented in each service. Retry policies, timeouts, and rate limiting follow the same pattern. Organizations such as eBay, AutoTrader UK, and VMware have already adopted Istio in production, citing improvements in observability, security, and operational simplicity.
Distributed tracing and observability without instrumentation. Tracing a single request across multiple microservices requires recording timing and context information at each hop. Without a mesh, this requires each service to propagate trace context headers and export telemetry to a tracing backend. Different teams implement this differently. Some services are fully instrumented. Some are not. The result is observability that has gaps exactly where the interesting failures happen.
Istio's sidecar proxies capture request timing and metadata at every service boundary automatically. Grafana, Prometheus, and Jaeger integrations are built in. Platform teams get distributed tracing across the entire cluster without asking development teams to change their services. This capability, combined with the security model, is typically what convinces engineering leadership to absorb the operational overhead Istio introduces.
Resilience patterns applied cluster-wide. Health checks, automatic failover, and load balancing configuration that would otherwise require per-service implementation are applied uniformly across the mesh. P99Soft's Service Mesh and Istio Support practice implements exactly these patterns, including the VirtualService configuration for canary routing, DestinationRule setup for circuit breaking, and PeerAuthentication policies for mTLS enforcement across different namespace boundaries.
Istio Architecture: Sidecar Mode vs Ambient Mode
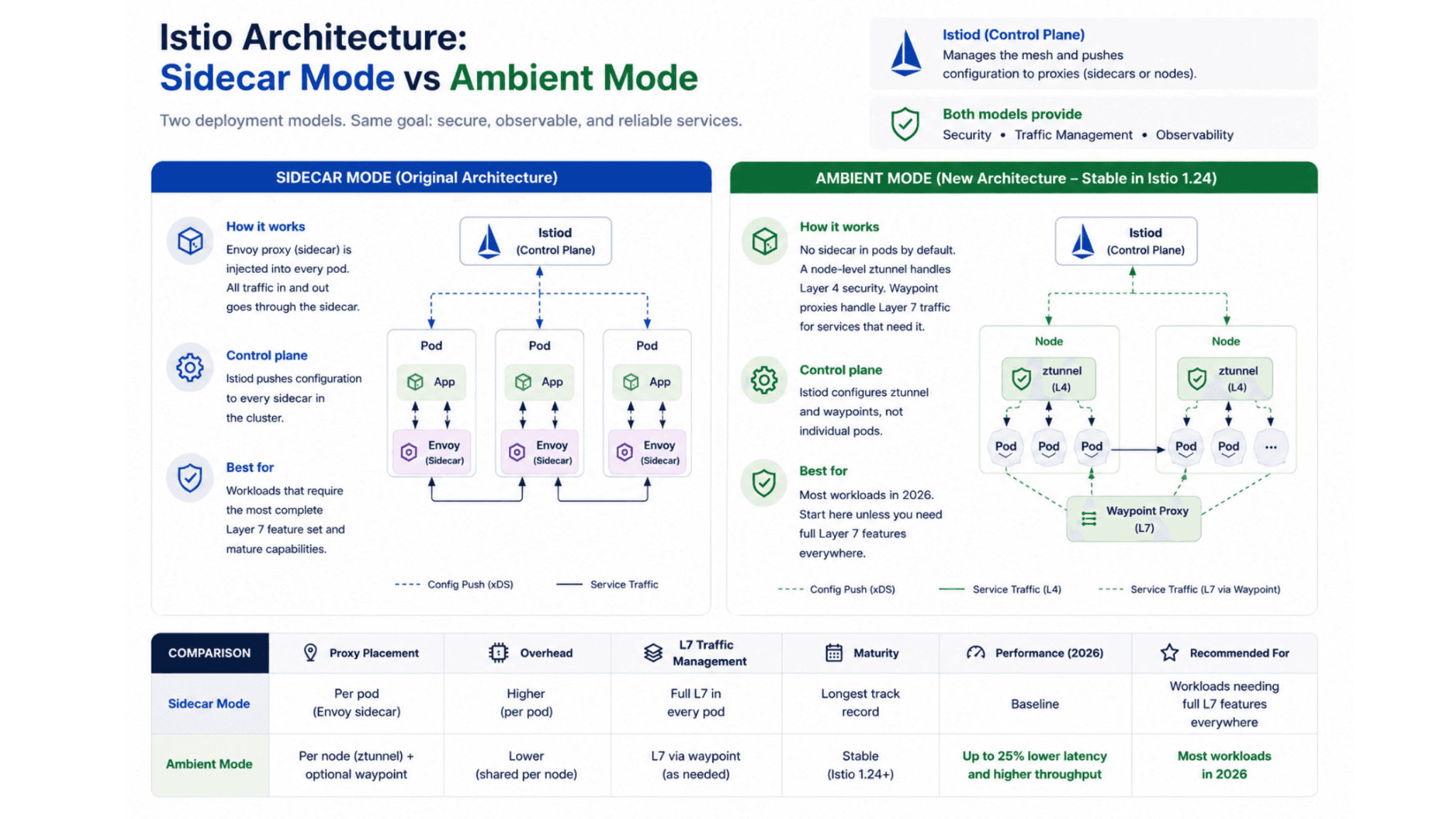
Istio's architecture has changed significantly in the last two years, and understanding both deployment models matters for teams evaluating it in 2026.
Sidecar mode is the original Istio architecture. Every pod in the mesh gets an Envoy proxy container injected alongside the application container. All traffic into and out of the pod passes through that sidecar proxy. The control plane, Istiod, pushes configuration to every sidecar in the cluster. Sidecar mode provides the most complete feature set and has the longest production track record.
The operational cost of sidecar mode is memory and CPU overhead per pod. Each Envoy sidecar consumes resources regardless of whether the pod is actively handling traffic. In large clusters with hundreds of services and thousands of pods, this overhead adds up. Rappi, the Latin American super-app, ran Istio across more than 50 Kubernetes clusters with the largest running over 20,000 containers. After implementing Istio, Rappi found themselves better equipped to handle their explosive growth, with Istio enabling them to manage the infrastructure complexity their scale required.
Ambient mode is Istio's newer architecture, promoted to stable in Istio 1.24. Instead of injecting a sidecar into every pod, ambient mode uses a node-level component called ztunnel that handles the Layer 4 security functions, and a waypoint proxy that handles Layer 7 traffic management for services that need it. Performance benchmarks from 2026 show ambient mode provides up to 25% lower latency and higher throughput compared to sidecar-based configurations, making it a preferred choice for cloud-native environments.
Ambient mode reduces per-pod overhead significantly because the proxy is shared across all pods on a node rather than duplicated for each pod. For organizations evaluating Istio for the first time in 2026, ambient mode is the recommended starting point for most workloads. Sidecar mode remains relevant for services requiring the full Layer 7 feature set that waypoint proxies do not yet support in all configurations.
Why Engineering Teams Adopt Istio: The Real Drivers
Most Istio adoption decisions trace to one of three specific operational pressures rather than a general desire for better architecture.
A security audit or compliance requirement revealed that internal service communication was unencrypted. This is the most common adoption driver in regulated industries. A PCI DSS assessment, a SOC 2 audit, or a security architecture review identifies that microservices communicate over plain HTTP internally. The remediation options are either to add mTLS to every service individually, which is a large engineering program with inconsistent results, or to adopt a service mesh that enforces mTLS automatically. Istio's zero-trust networking model satisfies this requirement structurally rather than service by service.
A production incident that required tracing a request across multiple services exposed the absence of distributed observability. Engineering teams that have investigated a latency problem or a cascading failure across five or more services without distributed tracing understand the operational cost immediately. The incident takes four hours to diagnose instead of 20 minutes. Istio's automatic telemetry collection turns a difficult forensic exercise into a visual trace in Grafana.
Progressive delivery requirements outgrew what Kubernetes Deployments and Services support natively. Kubernetes provides rolling updates but not traffic splitting. A canary deployment that sends 5% of traffic to a new version while monitoring error rates requires a service mesh or an external traffic management tool. Teams that have grown sophisticated enough to want percentage-based canary releases, A/B traffic routing, or fault injection for chaos engineering find that Istio provides all of these through declarative configuration.
This third driver connects directly to Expert SRE Guidance practice. Error budget-driven deployments, where a team uses error budget consumption to decide whether to expand canary traffic or roll back, depend on both the traffic management capability Istio provides and the SLO measurement framework that SRE practices establish. The SRE Error Budgets Explained article covers how error budgets guide deployment decisions, which becomes significantly more precise when canary traffic splitting allows a team to expose 1% of users to a new version before committing to the full rollout.
When a Service Mesh Is Worth the Complexity
A service mesh adds operational complexity. Istio's control plane, certificate management, proxy configuration, and upgrade procedures require platform engineering investment that goes beyond deploying standard Kubernetes workloads. Adopting Istio before the problems it solves exist at your scale creates operational overhead without a corresponding benefit.
A service mesh is worth adopting when all of the following are true for your organization.
Your cluster runs more than 10 to 15 microservices in production. Below this threshold, the per-service approach to retry logic, encryption, and observability is manageable. The coordination overhead of implementing these patterns consistently across 10 services is not prohibitive. Above 20 services it becomes operationally expensive. Above 50 it becomes organizationally intractable.
You have had at least one production incident where the absence of distributed tracing made diagnosis significantly slower. One well-investigated incident that would have resolved in 15 minutes with tracing instead of 3 hours without it makes the value case better than any benchmark.
Your security requirements include encrypted and authenticated service-to-service communication. If your compliance posture, your security architecture review, or your threat model requires mTLS between internal services, Istio satisfies that requirement more completely and more maintainably than per-service implementation.
You have a platform team that will own the mesh as a product with ongoing investment. Istio without an owner is infrastructure debt. The control plane needs monitoring. Certificates need lifecycle management. Proxy configurations need to be kept current with cluster changes. If nobody will own this, the operational overhead will eventually fall on the development teams the mesh was supposed to help, which reverses the value proposition entirely.
A service mesh is not worth adopting when your team is still deploying a monolith or fewer than five services. When your engineering organization does not yet have a stable Kubernetes platform practice. When no compliance, security, or observability requirement exists that per-service implementation cannot address. Or when the platform team's roadmap has no capacity to absorb a new production system for the next two quarters.
Istio in the Broader Reliability and Platform Engineering Stack
Istio does not operate as a standalone system. It connects to the broader reliability and platform engineering infrastructure in ways that determine whether the operational investment pays for itself.
Cloud Networking Solutions determines the network topology that Istio operates within. Istio handles east-west traffic between services in a cluster. The underlying cloud networking architecture handles north-south traffic from users to the cluster edge, multi-cluster connectivity, and the private network configuration that determines which services can reach which others at the infrastructure level. Getting the network layer right before implementing a service mesh prevents the class of operational problems that come from Istio policies being applied to traffic that bypasses the mesh entirely.
Infrastructure Automation with Terraform manages the Istio installation itself. Treating Istio configuration as infrastructure as code, with version control, review processes, and automated application, prevents the configuration drift that makes mesh debugging difficult. An Istio deployment where PeerAuthentication policies, VirtualService configurations, and DestinationRule definitions are managed through code is auditable and recoverable. One where configuration accumulated through ad-hoc kubectl commands is not.
Backup and Disaster Recovery practice needs to account for Istio's certificate infrastructure and configuration state as part of cluster recovery procedures. A cluster restored without its Istio configuration loses the traffic management and security policies that governed service communication. Including Istio configuration in disaster recovery procedures ensures the mesh policies are restored with the workloads that depend on them.
For engineering teams earlier in the reliability journey, the What Is Site Reliability Engineering? guide covers how SRE practices connect to the infrastructure layer that Istio operates within. The SRE error budget model, where canary deployment decisions are driven by real-time error rate monitoring, works most precisely when Istio provides the traffic splitting control that makes incremental rollout measurable at the percentage level rather than the deployment level.
P99Soft's Service Mesh and Istio Support practice implements Istio for engineering organizations at the right point in their platform engineering maturity. The engagement covers the deployment model decision between sidecar and ambient mode, mTLS policy design across namespace boundaries, VirtualService configuration for traffic management, observability integration with Prometheus and Grafana, and the upgrade procedures that keep the mesh current without creating production risk.
FAQ
What is a service mesh and do I need one?
A service mesh is an infrastructure layer that manages how microservices communicate with each other, providing traffic management, security, and observability without changes to application code. You need one when your Kubernetes cluster runs more than 15 microservices and you have operational requirements for mutual TLS between services, distributed tracing across service boundaries, or canary traffic routing without application code changes. Below that threshold, per-service implementation of these patterns is manageable and the operational overhead of running a service mesh exceeds the benefit.
What does Istio do in a Kubernetes cluster?
Istio sits between every service in a Kubernetes cluster and manages their communication. It enforces mutual TLS so that every service-to-service connection is encrypted and authenticated automatically. It provides traffic management capabilities including canary routing, circuit breaking, retries, and timeouts configured through Kubernetes resources rather than application code. It collects distributed traces and telemetry at every service boundary and exports them to observability platforms like Prometheus and Grafana. All of this happens at the infrastructure level without requiring changes to the application containers.
What is Istio ambient mode and how is it different from sidecar mode?
Istio sidecar mode injects an Envoy proxy container into every pod in the mesh, which adds per-pod memory and CPU overhead but provides the full Istio feature set. Ambient mode uses a node-level component called ztunnel for Layer 4 security functions and a waypoint proxy for Layer 7 traffic management, eliminating the need for per-pod sidecars. Performance benchmarks from 2026 show ambient mode delivers up to 25% lower latency and higher throughput than sidecar mode. For teams adopting Istio in 2026, ambient mode is the recommended starting point for most workloads.
How long does it take to implement Istio in an enterprise Kubernetes environment?
A basic Istio implementation covering installation, namespace enrollment, mTLS policy activation, and observability integration takes two to four weeks for a single cluster with existing Kubernetes experience on the platform team. Extending to multi-cluster configurations, custom traffic management policies, and full integration with existing monitoring infrastructure typically takes six to twelve weeks depending on cluster complexity and the number of services requiring custom VirtualService configuration. Organizations attempting Istio implementation without a dedicated platform engineering team consistently underestimate the ongoing operational investment the mesh requires after initial deployment.