Legacy Modernization to Microservices: A Practical Guide to Scaling Cloud-Native Products Without Disruption

Legacy modernization to microservices succeeds when organizations migrate incrementally using the strangler fig pattern, extract services based on genuine domain boundaries rather than arbitrary code splits, and build the platform layer alongside the migration rather than after it. The single most common cause of failed modernization is treating it as a one-time project rather than a phased engineering program with measurable outcomes at each stage.
Legacy systems consume up to 80% of enterprise IT budgets, leaving almost nothing for innovation, new product development, or the AI capabilities that have become table stakes in most industries. This is not a new problem. It has been building for decades across financial services, healthcare, logistics, and manufacturing. What is new in 2026 is the urgency.
Nearly 60% of AI leaders cite legacy system integration as the primary barrier to deploying agentic AI, according to Deloitte research from 2025. That is not an IT problem. That is a strategy problem. Legacy systems were designed for batch processing and overnight data pipelines. Modern AI workloads need real-time data access, clean API surfaces, and millisecond inference. Most legacy architectures cannot provide any of those things without a fundamental change in how they are structured.
The decision to modernize is rarely the hard part. The hard part is doing it without breaking the systems the business depends on every day.
Why Most Legacy Modernization Projects Fail Midway
Legacy modernization fails most often not because of technical complexity but because of sequencing decisions made before the first sprint begins.
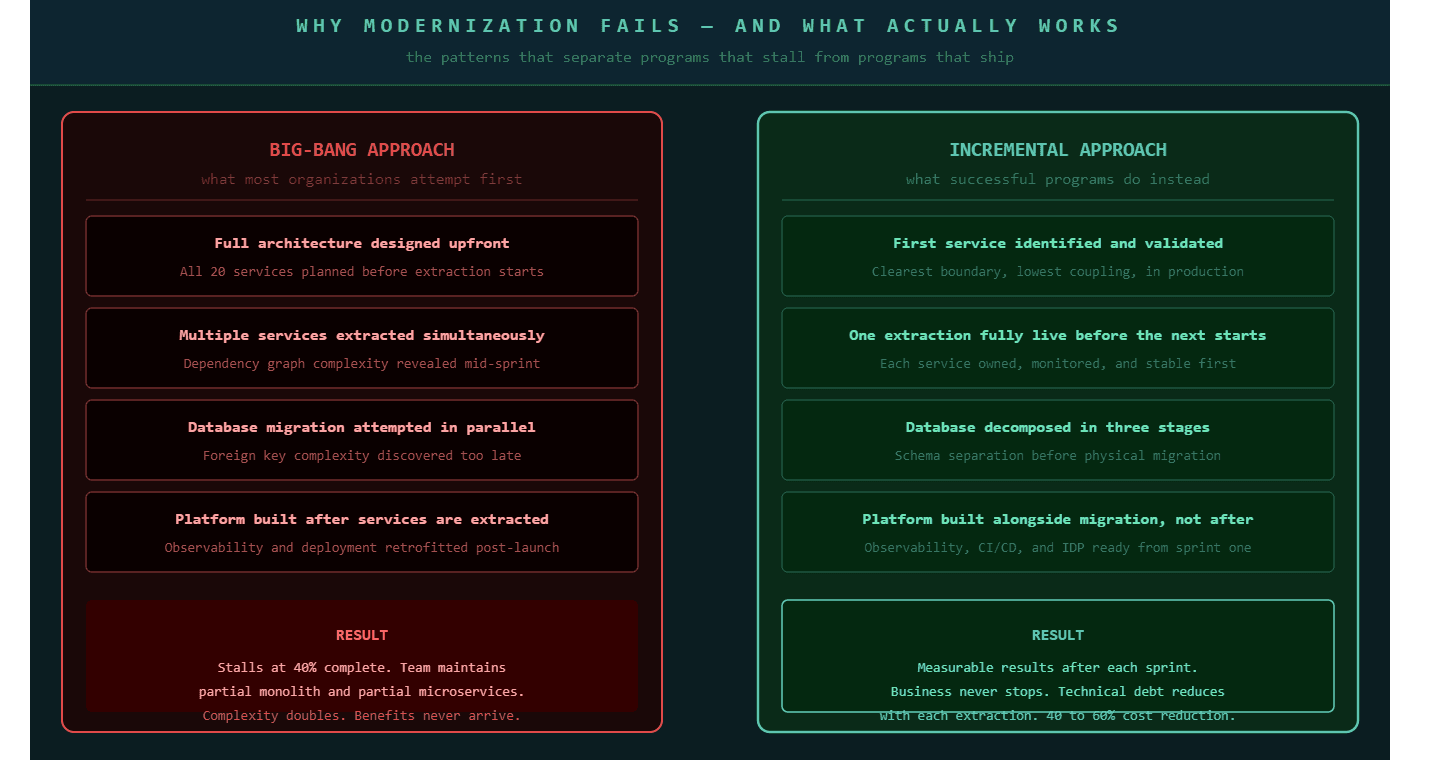
Legacy systems contain decades of accumulated business logic that nobody fully understands anymore. The original developers retired, documentation disappeared, and the applications continue running because replacing them feels impossible. When organizations attempt to extract this logic too quickly or too broadly, they discover the dependency graph is far more tangled than any planning document captured. The migration stalls at 40 percent complete and the engineering team ends up maintaining a partial monolith and a partial microservices environment simultaneously, carrying all the operational complexity of both with the benefits of neither.
Nobody wants a big-bang migration that locks up budget for two or three years and risks everything failing at once. The organizations that modernize successfully treat it as a continuous program of incremental extraction rather than a single transformation event. Each extracted service goes through full production validation before the next extraction begins. The legacy system keeps running throughout. The business never stops.
The architecture is rarely what breaks a modernization program. The sequencing is. Organizations that define clear extraction criteria, validate each service in production before moving to the next, and build organizational ownership alongside the technical work succeed at significantly higher rates than those who plan the full target architecture first and then attempt to build toward it all at once.
The Strangler Fig Pattern: The Safest Migration Path in Production
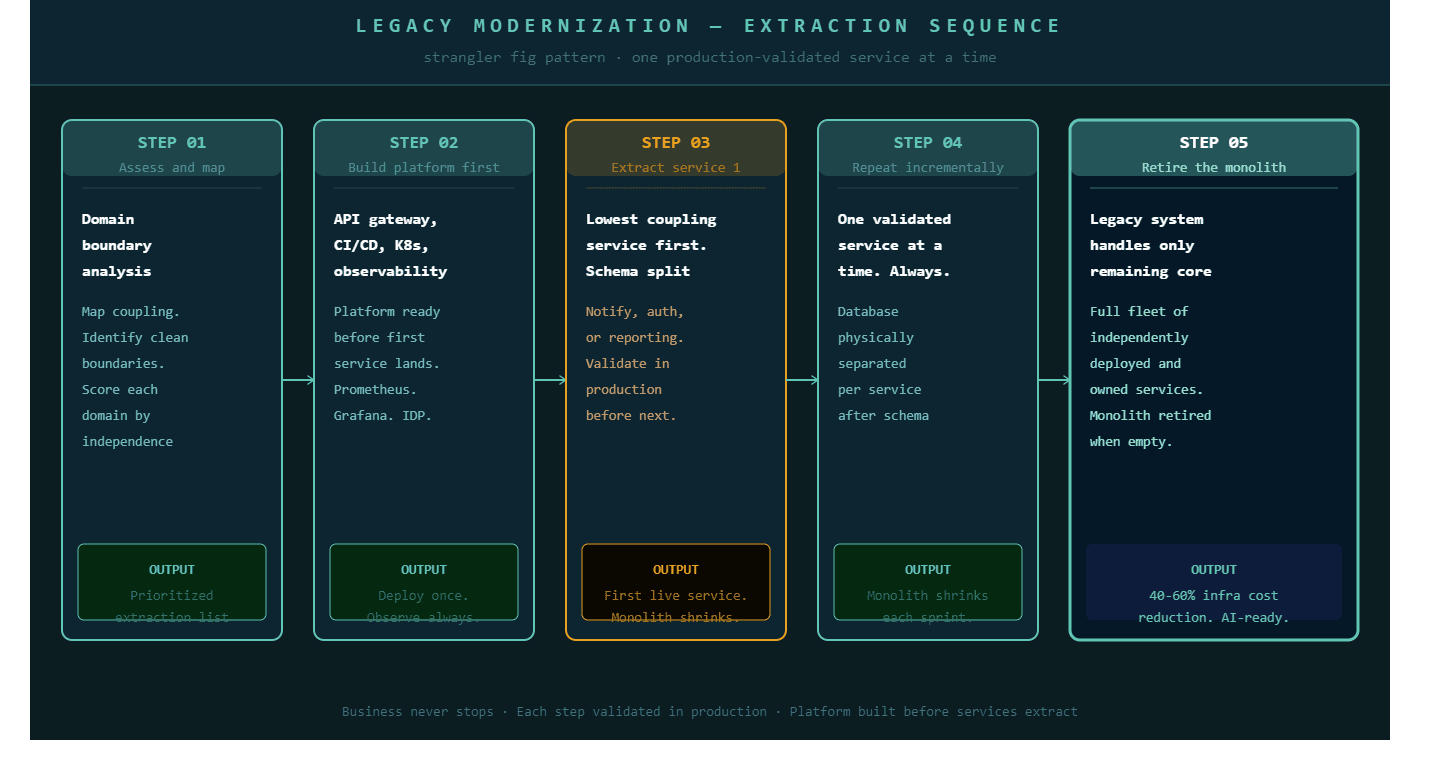
The strangler fig pattern enables organizations to refactor legacy applications step by step, replacing critical functions with cloud-native services while the existing system continues to operate. Named after a tree that grows around an existing structure and gradually replaces it, this pattern is the most battle-tested approach to legacy modernization in production environments.
The mechanics are straightforward. An API gateway sits between users and the application. New requests for specific business functions route to newly built microservices. All other requests continue hitting the legacy system. The legacy system shrinks as each function is extracted, validated, and transferred. At no point does the organization depend on a migration completing for the business to keep operating.
Netflix made this approach famous by migrating from a monolithic Java application to AWS microservices over several years without taking the streaming service offline. ING Bank and BBVA have been executing gradual core banking replacements for years while maintaining operational continuity. The strangler fig pattern functions as more than an architectural choice in these programs. It is an operational strategy that lets teams show measurable results after each sprint rather than asking boards to wait three years for a payoff.
The extraction sequence within this pattern follows a consistent logic. Services with the clearest, most independent boundaries go first: notification services, authentication flows, reporting modules, and document generation. These have well-defined inputs and outputs, low coupling to the rest of the system, and failures that do not cascade into the core business logic. The high-value, deeply coupled services, payment processing, core transaction logic, complex orchestration workflows, come later, after the team has built the operational competency to run distributed services reliably.
Database Decomposition: The Step That Determines Whether Migration Succeeds or Stalls
Every legacy modernization conversation focuses on application code. The database is where the real work lives, and where most programs encounter their first serious obstacle.
In a monolith, all services share one database. Tables reference each other through foreign keys. Business logic is sometimes encoded in stored procedures that live inside the database itself. When you extract a service from the application layer, that service still needs data. Getting data from a shared monolithic database creates a coupling that defeats the purpose of the extraction.
The correct sequence has three stages. First, introduce logical schema separation inside the shared database while still on the monolith. Each future service gets its own schema. Cross-schema foreign key dependencies are eliminated and replaced with application-level joins or API calls. This stage requires no deployment change and is fully reversible. Second, run the extracted service against the shared database through its dedicated schema. The service is physically separate but still reads from the shared database, which makes the transition observable and low-risk. Third, physically migrate the schema to the service's own database instance. At this point the service is genuinely independent.
API-first development has become standard practice in modernization projects, delivering integrations 3.9 times faster and enabling changes 5.6 times faster than traditional approaches. Designing APIs before building application features creates standardized interfaces that let different systems communicate reliably. When each service exposes clean API surfaces rather than sharing database state, the coupling that makes legacy systems rigid disappears, and each service can be changed, scaled, or replaced without touching anything else.
P99Soft's Legacy Modernization: Monolith to Microservices practice treats database decomposition as a parallel workstream alongside application extraction, not a consequence of it. Getting this sequencing right is what separates modernizations that deliver working microservices from ones that deliver loosely coupled services that still depend on a shared database.
Building the Platform Layer Alongside the Migration
One of the most consistent mistakes in legacy modernization is treating platform engineering as a future concern. Teams extract two or three services, discover they need consistent deployment automation, observability, and access control, and then spend months retrofitting infrastructure that should have been built from the start.
The platform layer, meaning the internal developer platform, CI/CD pipelines, Kubernetes configuration, and observability stack, needs to be operational before the first service extracts into production. Not because this is theoretically correct, but because without it, each extracted service requires custom deployment work and manual monitoring setup that compounds as the number of services grows.
Modern AI workloads need real-time data access, clean API surfaces, and continuous model training pipelines that legacy systems cannot provide. The same architectural foundations that enable AI adoption, clean APIs, event-driven data flows, independently deployable services, are exactly what cloud-native modernization produces. Organizations that modernize with AI readiness in mind structure their extraction sequence to prioritize the services that most directly feed data workloads.
P99Soft's Cloud Product Engineering at Scale practice addresses this directly. Platform engineering and modernization are not sequential workstreams in our engagements. They run in parallel. Services extracted from the monolith land on a platform that already knows how to deploy, observe, and operate them. Kubernetes Optimization ensures the infrastructure running those services is configured correctly from the first deployment rather than accumulating the resource waste that comes from default configurations applied at launch and never reviewed.
When a Modular Monolith Is the Right Answer
Not every organization that has a monolith needs microservices. This is a point worth stating plainly because the industry conversation around microservices has created the impression that monoliths are inherently wrong.
In 2025 and 2026, many organizations are choosing a modular monolith as the destination for their modernization program rather than full microservices, getting architectural separation without the operational overhead of a fully distributed system. A modular monolith is a single deployable unit with clearly separated internal modules, each with its own domain logic, data access layer, and defined interfaces. It deploys as one service but behaves with the separation of concerns that makes code maintainable and teams independent.
For teams below 15 developers, or for organizations whose traffic is uniform across all features without independent scaling requirements, a modular monolith delivers most of the modernization benefits with a fraction of the operational complexity. Kubernetes, service meshes, distributed tracing, inter-service network latency, and the API contracts that microservices require between every component are all costs that only pay for themselves at a specific scale.
The decision criteria are the same three questions from any microservices evaluation: Does the system have independent scaling needs where different modules carry significantly different traffic? Does the team have more than 10 to 15 engineers actively working across the codebase? Is the deployment cycle actively blocking feature delivery because of coordination overhead? If any of these is no, a modular monolith may be a better destination than full microservices.
How Legacy Modernization Connects Across Cloud Services
Legacy modernization does not exist as an isolated workstream. Every architectural decision made during extraction connects to the broader cloud strategy the engineering organization is building toward.
Serverless Cloud Solutions frequently become the right execution model for services extracted from a monolith that have event-driven, variable-load characteristics. A notification service, a document generation workflow, or an async data processing job often fits serverless deployment better than a dedicated Kubernetes pod. Enterprises can maintain full business continuity with zero unplanned downtime throughout the modernization journey using incremental, phased approaches. Kubernetes Optimization ensures the services that do land in Kubernetes are configured correctly from the start rather than accumulating resource waste through default configurations. And Cloud Product Engineering at Scale provides the platform layer that makes every extracted service deployable, observable, and maintainable without bespoke engineering effort per service.
P99Soft's Legacy Modernization: Monolith to Microservices practice works across all of these layers simultaneously. Domain boundary analysis and extraction sequencing happen in the first weeks. Platform engineering and CI/CD automation run in parallel. Database decomposition follows the three-stage schema-first approach. And every service that extracts lands on infrastructure that already knows how to run it, observe it, and scale it. A focused modernization approach can cut deployment errors by 30% and accelerate releases by 40%, with developers able to ship new features without touching everything at once. Those outcomes come from doing the work in the right order, not just doing more of it.
FAQ
What is legacy modernization to microservices and how long does it take?
Legacy modernization to microservices is the process of extracting functionality from a monolithic application into independently deployable services, each owning its own data and communicating through APIs. The timeline depends on the size of the monolith, the number of services being extracted, and the complexity of the underlying data model. Most enterprise programs see meaningful production results within three to six months using incremental extraction, with the full modernization program spanning one to three years depending on scope. Organizations that attempt big-bang migrations rarely complete them.
What is the strangler fig pattern and why is it the preferred modernization approach?
The strangler fig pattern is a migration strategy where an API gateway routes specific requests to newly built microservices while the legacy system continues handling all other traffic. New functionality is built as microservices from the start. Existing functionality is extracted incrementally, service by service, with each extraction fully validated in production before the next begins. It is the preferred approach because the legacy system keeps running throughout, the business never depends on the migration completing, and teams can demonstrate measurable results after each sprint rather than waiting years for a payoff.
How do you migrate from a monolith to microservices without downtime?
The strangler fig pattern combined with an API gateway prevents downtime during migration. The legacy system handles all traffic until a specific service is extracted, validated, and routed to the new microservice. At no point does traffic move to a service that has not been fully tested in production. Database decomposition follows a three-stage approach: logical schema separation inside the shared database first, then running the extracted service against the shared database through its own schema, then physically migrating the schema to the service's own database instance. Each stage is reversible and observable.
When should you use a modular monolith instead of microservices?
A modular monolith is the right modernization destination when your team is below 10 to 15 developers, when your traffic is relatively uniform across all system features without genuine independent scaling requirements, or when your deployment cycle is not blocked by coordination overhead between teams. Microservices deliver their benefits at scale, but they also introduce distributed system complexity, network latency between services, and operational overhead that exceeds the advantages for smaller teams and simpler workloads. A modular monolith delivers architectural separation without those costs.