Kubernetes Optimization and Innovation: Reducing Costs, Improving Performance, and Scaling Workloads in Production |

Kubernetes optimization in production combines resource rightsizing, intelligent autoscaling, FinOps discipline, and observability to close the gap between provisioned capacity and actual workload usage. Organizations that treat this as an ongoing engineering practice rather than a one-time configuration reduce cloud costs by 30 to 50% while improving reliability and deployment speed simultaneously.
There is a specific number that every engineering leader running Kubernetes in production should sit with for a moment.
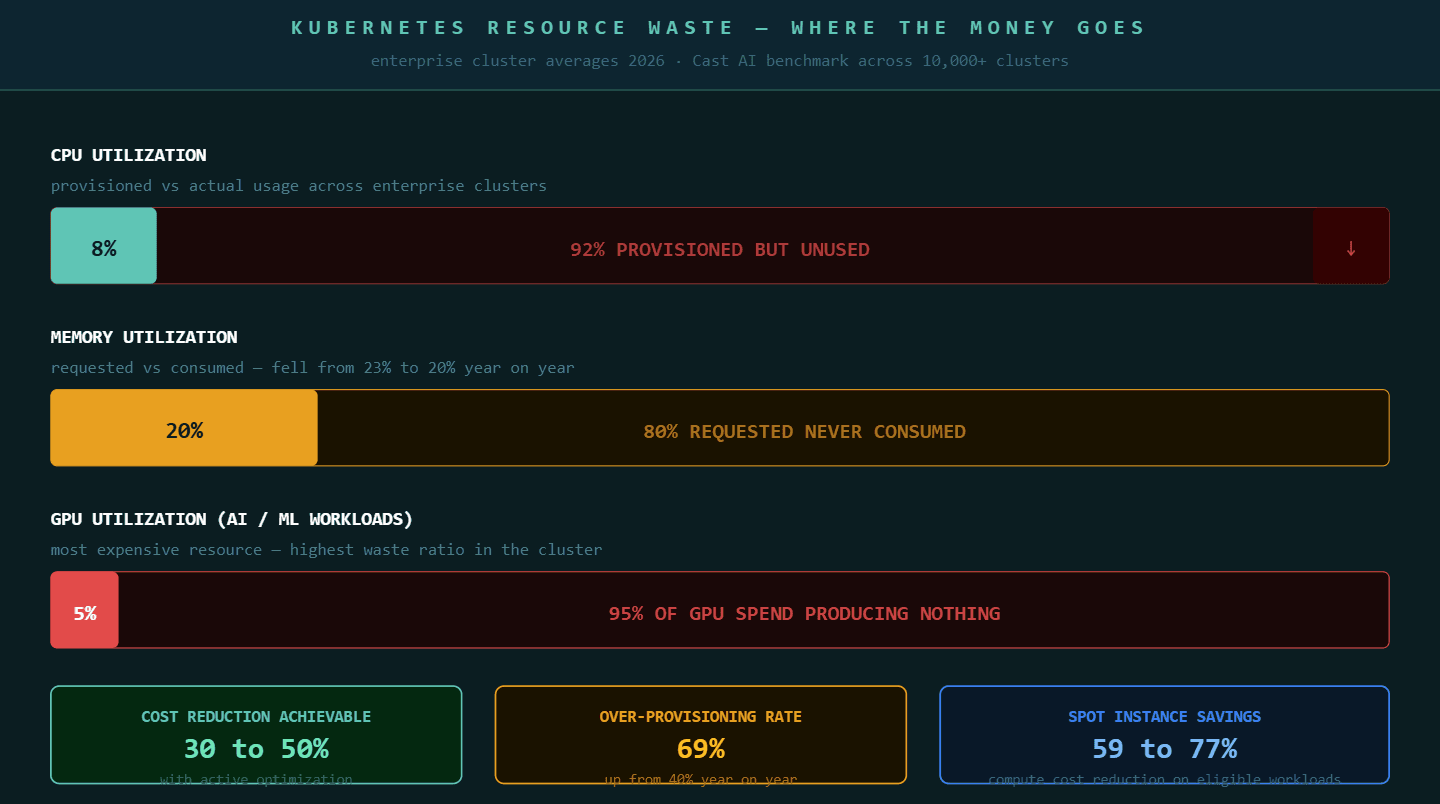
Average CPU utilization across enterprise Kubernetes clusters sits at 8% in 2026, down from 10% the year before. Memory utilization has fallen from 23% to 20%. GPU utilization across AI and machine learning workloads averages 5%. These are not edge cases from teams that are new to Kubernetes. These are averages drawn from tens of thousands of clusters across AWS, Azure, and Google Cloud.
Put plainly: most organizations running Kubernetes are paying for capacity their workloads never touch.
96% of enterprises are now running Kubernetes, yet studies show only 13% of the requested CPU is actually used on average, while 20 to 45% of requested resources actually power workloads. The remaining provisioned capacity exists because developers set resource requests at deployment, nothing challenged those numbers, and the cluster kept paying for them through every low-traffic hour, every weekend, and every seasonal dip since.
Kubernetes optimization is what changes that. Not by cutting corners on reliability, but by closing the gap between what is provisioned and what is actually needed.
Why Kubernetes Costs Grow Without Active Management
Kubernetes cost growth is predictable when you understand its causes. According to the CNCF microsurvey on cloud-native FinOps, the top reasons for rising Kubernetes costs are over-provisioning at 70%, lack of ownership and accountability at 45%, and unused resources and technical debt at 43%.
Over-provisioning is the most common and the most correctable. When a developer configures a pod with a CPU request of 2 cores because the application sometimes needs that during peak traffic, the cluster reserves those 2 cores permanently. If actual utilization is 200 millicores most of the time, 1.8 cores sit reserved and unused every hour the pod runs. Multiply that across hundreds of services and thousands of pods and the waste compounds rapidly.
Lack of ownership accountability amplifies the problem. When no team is responsible for the cloud cost their services generate, nobody has incentive to revisit resource configurations after the initial deployment. Requests set at launch become permanent defaults. CPU over-provisioning rose from 40% to 69% year on year in the latest benchmark data, meaning the gap between provisioned and used capacity is growing faster than adoption itself.
Unused resources compound the bill further. Development and staging environments left running at full capacity overnight and on weekends. Orphaned persistent volumes from deleted workloads. Old namespaces nobody shut down after a project ended. Each of these adds cost that delivers no value and requires active governance to surface and remove.
Key Takeaway: Kubernetes cost growth is not a Kubernetes problem. It is a configuration and governance problem that Kubernetes makes visible at scale. Active optimization closes the gap between provisioned capacity and actual usage without compromising the reliability the organization depends on.
The Three Levers of Kubernetes Cost Reduction
Effective Kubernetes optimization reduces costs by 30 to 50% without degrading application performance. The organizations achieving those reductions consistently pull the same three levers, applied in a sequence that builds on each prior step.
Lever 1: Rightsizing pod resource requests and limits
Rightsizing is the practice of setting CPU and memory requests to match what workloads actually consume rather than what developers estimated they might need at peak. The Vertical Pod Autoscaler (VPA) automates much of this by analyzing observed usage patterns and adjusting requests accordingly. Where VPA is not appropriate for live adjustment, the same analysis informs manual configuration reviews.
The challenge with rightsizing is that it requires visibility before it requires action. Engineers need per-pod utilization data, not just cluster-level averages, to understand which services are the largest contributors to waste. Namespace-level cost allocation and pod-level metrics are prerequisites, not optional enhancements.
Lever 2: Autoscaling configured to match workload behavior
The Horizontal Pod Autoscaler (HPA) scales the number of pods based on CPU utilization, memory, or custom metrics, and 86% of HPA users apply it across most of their clusters, making it a foundational part of Kubernetes resource management. HPA handles demand spikes without requiring static peak provisioning, which eliminates the most common justification for chronic over-provisioning.
HPA and VPA work at the pod level. Node-level autoscaling, through Cluster Autoscaler or the newer Karpenter on AWS, handles the infrastructure beneath the pods. When these two layers are configured consistently, clusters shrink during low-traffic periods and expand during bursts without manual intervention. The result is an infrastructure footprint that tracks actual demand rather than theoretical peaks.
Lever 3: Spot and preemptible instances for fault-tolerant workloads
Clusters optimized with partial usage of spot instances recorded an average of 59% compute cost savings. Clusters running only on spot instances recorded an average of 77% savings. For workloads that can tolerate interruption, batch processing jobs, development environments, background workers, and stateless services with sufficient replicas, spot instances represent the largest single source of immediate cost reduction available in any cloud provider.
The engineering work required is Kubernetes node configuration using node selectors and taints to ensure only appropriate workloads schedule onto spot nodes, combined with graceful shutdown handling to manage interruptions without affecting users.
How to Scale Kubernetes Workloads Without Losing Performance
Cost reduction and performance improvement are not opposing goals in Kubernetes. Most of the practices that reduce cost also improve performance because they eliminate the resource contention and misconfiguration that creates latency and instability.
Namespace and cluster isolation for different workload profiles. Production, staging, and development workloads behave differently and should not compete for the same cluster resources. Isolating them into separate namespaces with resource quotas enforced at the namespace level prevents development activity from affecting production latency and makes cost attribution accurate at the team level.
Resource limits that prevent noisy neighbor problems. Pods without CPU limits can consume unbounded resources during traffic spikes, affecting every other workload on the same node. Setting appropriate limits, informed by observed usage patterns rather than guesswork, is what prevents a single misbehaving service from degrading the entire cluster's performance profile.
Observability as an operational requirement, not an add-on. You cannot optimize what you cannot measure at the right level of granularity. Prometheus and Grafana give engineering teams the per-pod, per-namespace metrics needed to identify which workloads are over-provisioned, which are under-resourced, and which are the primary drivers of cluster cost. Without this visibility, optimization is guesswork. With it, every configuration decision is grounded in actual data.
The Kubernetes Optimization and Innovation practice at P99Soft works at all three levels simultaneously, combining rightsizing analysis, autoscaling configuration, and observability infrastructure into an optimization engagement that delivers measurable results rather than recommendations.

Where Kubernetes Optimization Connects to Broader Cloud Architecture
Kubernetes does not operate in isolation from the rest of a cloud product engineering strategy. The optimization decisions made at the cluster level connect directly to architecture decisions made across the full system.
The workload placement question is the most consequential connection. Not every workload belongs in Kubernetes. Services with highly variable, event-driven traffic often cost less and operate more reliably on Serverless Cloud Solutions, where the execution model scales to zero between invocations rather than maintaining pod replicas through idle periods. Kubernetes serves stateful, latency-critical, and consistently loaded services better than serverless does. Assigning each workload to the right execution model reduces the total infrastructure footprint while improving the performance of each individual service.
The modernization connection is equally direct. Organizations that move from a monolith to microservices as part of Legacy Modernization work frequently land their extracted services on Kubernetes for the first time. The resource configuration patterns that produce efficient clusters need to be established when services first deploy, not retrofitted after years of accumulated overprovisioning. This is why P99Soft's modernization engagements include Kubernetes configuration guidance as part of the migration work itself, not as a follow-on optimization project.
At the platform layer, Cloud Product Engineering at Scale provides the organizational and platform engineering foundations that make Kubernetes optimization sustainable. When platform teams own cluster governance, define resource request standards, enforce cost tagging policies, and maintain the internal developer platform abstractions that protect product teams from raw Kubernetes complexity, the optimization practices established during an engagement hold over time rather than degrading as teams rotate and configurations drift.
What Kubernetes Innovation Looks Like in 2026
Beyond cost reduction, Kubernetes is evolving to support new classes of workload that were not design considerations when most organizations first adopted it.
GPU-aware scheduling is the most significant development. Kubernetes is evolving in 2026 to support AI workloads through GPU-aware scheduling optimizations and more advanced workload orchestration. With GPU utilization averaging 5% across enterprise clusters and AWS increasing H200 Capacity Block prices by 15% in January 2026, the cost of inefficient GPU scheduling is substantial. Organizations running AI and ML workloads in Kubernetes need specialized node pools, GPU resource quotas, and workload placement rules that treat GPU time as a scarce, expensive resource rather than general compute.
Arm-based compute nodes are another area of active innovation. Arm nodes grew 3.5 times faster than x86 nodes between mid-2024 and the end of 2025, now accounting for around 9% of deployments, driven by the price-performance advantage of processors such as AWS Graviton for stateless containerized workloads. For organizations running large fleets of stateless services, migrating eligible workloads to Arm nodes delivers meaningful cost reduction without requiring architecture changes.
Multi-cluster and multi-cloud Kubernetes governance is maturing in response to the growing number of organizations that operate more than one cluster across more than one cloud provider. The tooling and practices for consistent security policy, unified observability, and workload portability across clusters have advanced significantly, but organizations that manage this complexity without a deliberate strategy accumulate operational overhead that can consume the flexibility advantage multi-cluster deployment was supposed to provide.
How P99soft Approaches Kubernetes Optimization
The Kubernetes Optimization and Innovation practice at P99Soft starts with the visibility layer because optimization cannot happen without measurement at the right granularity. Every engagement begins with a cluster audit that produces a waste map: cost and utilization by namespace, by workload, and by team. That map becomes the prioritization framework for every subsequent action.
The optimization work follows the five-step sequence: visibility first, then rightsizing, then autoscaling configuration, then spot adoption for eligible workloads, then FinOps governance structures that keep the savings from drifting back. Each step produces measurable results before the next begins, which means every phase of the engagement delivers return before the following phase starts.
The goal is not a one-time cost reduction. It is an engineering organization where resource configuration is treated as an ongoing practice, reviewed regularly, governed consistently, and connected to the business outcomes the infrastructure is there to support.
FAQ
What is Kubernetes optimization and why does it matter in production?
Kubernetes optimization is the ongoing practice of configuring cluster resources, autoscaling, and workload placement to match actual usage rather than provisioned capacity estimates. It matters in production because the average enterprise Kubernetes cluster uses only 8% of its provisioned CPU. The remaining 92% is reserved and paid for but generating no value. Active optimization closes this gap and delivers 30 to 50% cost reduction without degrading application performance or reliability.
How do you reduce Kubernetes costs without affecting performance?
The most effective approach combines pod resource rightsizing using Vertical Pod Autoscaler or manual configuration review, Horizontal Pod Autoscaler for demand-responsive scaling, node-level autoscaling to shrink infrastructure during low-traffic periods, spot instances for fault-tolerant workloads, and FinOps cost allocation that makes each team accountable for the cloud spend their services generate. These practices reduce cost by eliminating waste rather than by reducing the resources available to workloads that actually need them.
What is Kubernetes rightsizing and how does it work?
Kubernetes rightsizing is the process of setting CPU and memory requests for pods to match their actual observed usage rather than developer estimates. When a pod requests 2 CPU cores but consistently uses 200 millicores, the other 1.8 cores are reserved and billed but never used. Rightsizing identifies these gaps through per-pod utilization data from tools like Prometheus, then adjusts requests to match observed usage at the 95th percentile, which preserves headroom for traffic spikes while eliminating chronic overprovisioning.
How does Kubernetes connect to a broader cloud product engineering strategy?
Kubernetes serves stateful, latency-critical, and high-throughput workloads as part of a broader cloud architecture that typically also includes serverless for event-driven services and managed cloud services for specific capabilities. The workload placement decisions, which services run in Kubernetes versus serverless versus managed compute, have significant impact on both cost and performance. Platform engineering practices that govern cluster configuration, cost tagging, and access control make Kubernetes optimization sustainable over time rather than requiring repeated remediation as teams and configurations change.