CI/CD Pipeline Optimization for Faster Software Delivery: Best Practices for Enterprises in India and Global Teams

Software delivery speed is a competitive advantage in a way it simply was not five years ago. The engineering teams that can take a feature from commit to production in hours rather than weeks do not just ship faster. They learn faster, respond to customers faster, and reduce the risk that what they built is wrong before it has cost the business significantly.
The DevOps market is projected to reach $25.5 billion by 2028, growing at 19.7% from 2023, driven by forward-looking organizations worldwide adopting CI/CD pipelines to accelerate release cycles and minimize support time by up to 60%. India specifically has become one of the most active engineering markets in this shift. JetBrains' State of CI/CD survey gathered insights from 805 participants worldwide, with strong representation from the United States, India, and several European countries, most working in software development, DevOps engineering, and technical leadership roles.
The bottleneck for most enterprises is not that CI/CD exists. It is that the pipeline was set up, never optimized, and has been slowly accumulating technical debt while the engineering team grew around it. Build times that were acceptable at ten developers become intolerable at fifty. Test suites that passed quickly when the codebase was small now take forty-five minutes and get retried instead of fixed. Security checks added after a compliance audit sit in the wrong place in the pipeline and slow every commit whether or not they find anything.
This article is about fixing that, specifically for enterprise teams in India and distributed global engineering organizations where the pipeline serves developers across multiple time zones, multiple repos, and multiple product lines simultaneously.
Why CI/CD Pipelines Degrade Over Time in Enterprise Environments
A pipeline that worked well at a certain team size and codebase complexity will not automatically continue working well as both grow. The degradation is predictable and the causes are consistent across engineering organizations everywhere.
Build time accumulates without anyone being accountable for it.
When a build that used to take eight minutes now takes thirty-five, it almost never happened in one incident. It happened in increments. A new test suite was added. A dependency scan was appended to the end of the pipeline. An integration test that used to be optional became mandatory. Each individual addition seemed reasonable. The aggregate result is a pipeline that context-switches developers out of their flow state every time it runs.
Security and compliance requirements get bolted on rather than built in.
By 2026, DevSecOps is no longer optional but a fundamental requirement for any mature DevOps practice. Pipelines must integrate security checks that scan container images for known vulnerabilities and fail builds if secrets are hard-coded in code. When these checks are added as late-stage audit responses rather than designed into the pipeline from the start, they add time without integrating with the build information that would make them fast and targeted.
Flaky tests get retried instead of fixed.
Among the most common CI/CD pain points is the presence of flaky tests, tests that fail intermittently without a corresponding code problem. Teams recognize AI's potential for identifying and resolving these, but most are still waiting for the ecosystem to mature before committing to wider AI adoption in the pipeline. In the meantime, flaky tests that get retried rather than fixed waste compute, waste developer time, and gradually erode trust in the pipeline's signal.
The pipeline has no owner. When no engineer or team is responsible for pipeline performance the way product teams are responsible for application performance, the degradation compounds without any counterforce. Builds slow. Tests become unreliable. Deploys require manual steps that accumulated when someone found a workaround and never removed it.
Key Takeaway: CI/CD pipeline degradation is not a tool problem. It is a governance problem. The pipeline needs an owner, a performance budget, and a regular review cycle the same way any other production system does.

Best Practice 1: Build Speed Is a Product Feature, Not a Nice-to-Have
The ten-minute rule exists for a reason. When a CI build takes longer than ten minutes, developers stop waiting for it. They context-switch to another task. When the build result eventually arrives, they have to re-enter the mental context of the code they were working on. That re-entry costs time and increases the chance of introducing new problems while fixing the original one.
For enterprise teams in India working across IST and overlapping with US-based product owners, build speed carries an additional cost. A developer who pushes code at 6pm IST and waits forty-five minutes for a result has lost the overlap window with their counterparts in North America. Feedback that could have been addressed in the same working day now crosses time zones.
Three interventions produce the most significant build time improvements consistently:
Parallel job execution runs independent pipeline stages simultaneously rather than sequentially. Unit tests, lint checks, and security scans that previously ran one after another can run at the same time. Total pipeline time becomes the duration of the slowest parallel job rather than the sum of all jobs.
Dependency caching avoids re-downloading packages that have not changed since the last build. In a Node.js application, npm install on every build can add four to eight minutes to pipeline time. Caching the node_modules directory and invalidating only when the package-lock.json changes makes that step take seconds instead of minutes. The same principle applies to Maven, Gradle, pip, and every other package manager in common use.
Selective test execution triggers only the tests related to changed code on pull request builds. The full test suite still runs before production deployment. But a change to the authentication service does not need to wait for the full suite covering payment processing, reporting, and notifications. On larger codebases this optimization alone can reduce PR build time by 40 to 60 percent.
These three practices together are the foundation of what P99Soft's CI/CD and Developer Experience practice establishes in every pipeline optimization engagement before anything else is addressed. Speed improvements at the build layer compound through every stage that follows.
For a deeper view of how these practices apply to specific pipeline architectures, our blog on CI/CD Pipeline Best Practices That Engineering Teams Actually Use in 2026 covers the implementation detail.
Best Practice 2: Security Gates Belong Inside the Pipeline, Not Outside It
The single most common compliance-related pipeline problem in enterprise environments is security tooling that was added after an audit requirement surfaced rather than designed into the pipeline architecture. When security scanning is appended to the end of a pipeline that was not built to support it, the results are predictable: slow scans that block deployment, false positives that developers learn to ignore, and a security gate that is technically present but practically ineffective.
By 2026, effective pipelines automatically scan container images for known vulnerabilities and fail builds when secrets are hard-coded in code. These checks integrated into CI/CD are what make security intrinsic rather than supplemental to the delivery process.
The four security checks that every enterprise pipeline needs, built into the pipeline at the right stage rather than appended at the end:
Static Application Security Testing (SAST) runs on the source code before it is compiled or deployed, catching injection vulnerabilities, insecure patterns, and hardcoded credentials at the point of earliest intervention.
Dependency scanning checks every third-party package your application pulls against known vulnerability databases. A library that was safe last quarter may have a critical CVE this quarter. This check should run on every build against the current dependency lock file.
Container image scanning validates the Docker images being pushed to your registry before they are deployed anywhere. Base image vulnerabilities, outdated layer packages, and misconfigured permissions are caught here before they become production exposure.
Secrets detection scans every commit for accidentally included API keys, database credentials, tokens, and certificates. These are responsible for a significant proportion of production security incidents and they are entirely preventable with a pipeline check that takes seconds.
For enterprise teams in India where regulatory requirements increasingly align with GDPR, SOC 2, and ISO 27001, building these controls into the delivery pipeline is both a security practice and a compliance posture. It demonstrates to auditors that security enforcement is structural rather than periodic.
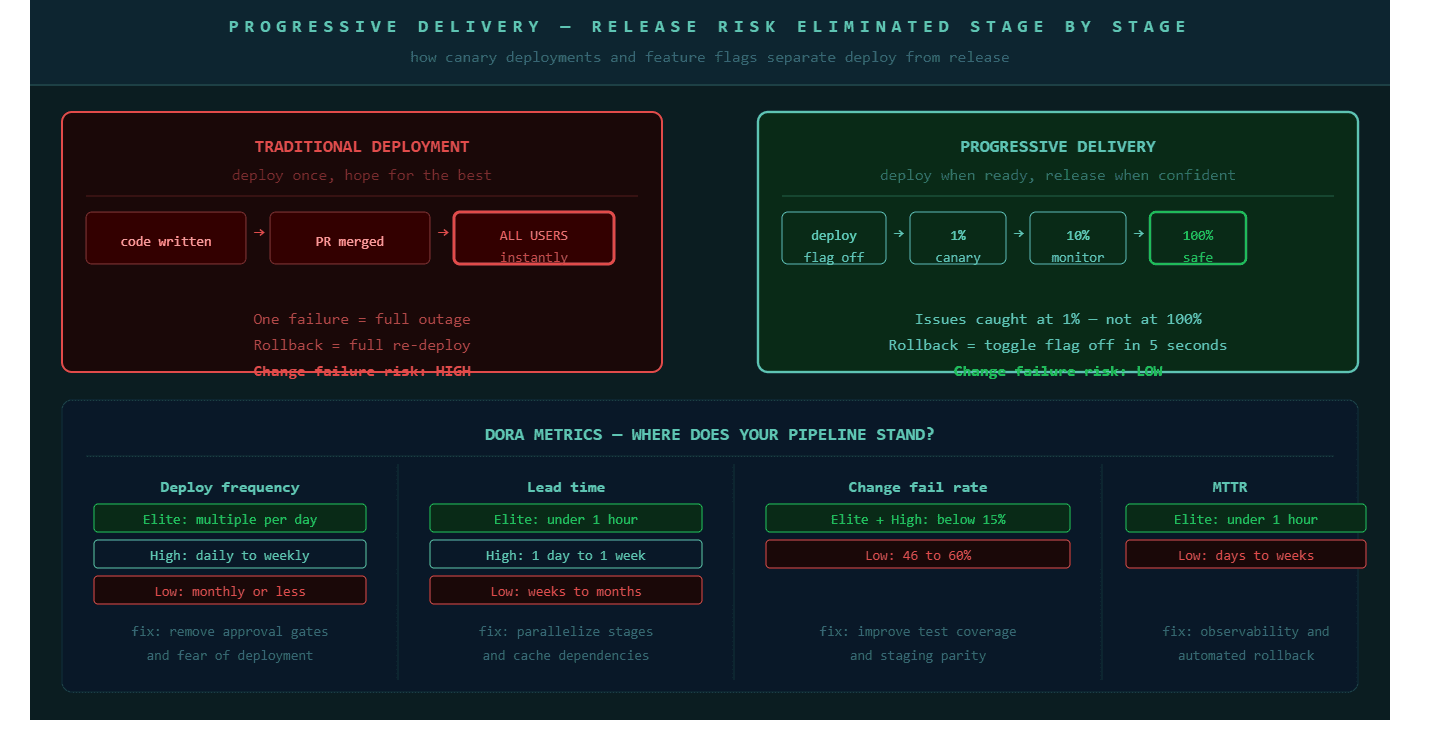
Best Practice 3: Progressive Delivery Removes the Risk From Every Release
Progressive delivery is the deployment strategy that involves gradually rolling out new features or updates to users using feature flags and canary releases. By 2026, it has become a key practice for minimizing risk and ensuring a smooth user experience. Risk mitigation through gradual rollouts allows teams to identify and address issues before they affect all users.
The core insight behind progressive delivery is that deployment and release are two separate decisions that most organizations treat as one. Deployment means code reaches a server. Release means users can see the feature. Separating these two events removes most of the risk associated with a production deployment.
Feature flags allow code to reach production in a dormant state. The feature is deployed but no user sees it. When the business decides to release it, the flag is toggled on. The release can start with one percent of users, expand to ten percent, and reach one hundred percent while the engineering team monitors error rates, latency, and behavioral signals at each step. If anything looks wrong, the flag turns off in seconds and no rollback deployment is required.
Canary deployments take a similar approach at the infrastructure level. A new version of the application is deployed to a small subset of servers or pods. Production traffic is gradually shifted to the new version as health checks confirm it is performing correctly. Automated rollback triggers revert the shift if the canary shows degraded performance without requiring a human to make the decision.
P99Soft's Progressive Delivery practice implements both capabilities for enterprise teams, with the observability infrastructure needed to make automated rollback decisions trustworthy rather than reactive.
Best Practice 4: Platform Engineering Is What Makes CI/CD Optimization Sustainable
Individual pipeline improvements made by individual teams do not accumulate into organizational improvement unless a platform layer enforces them consistently. This is the difference between a team that optimized their pipeline and an engineering organization that has fast, reliable delivery as a structural property.
Reusable pipelines that follow DRY principles through templates and inheritance are a key characteristic of enterprise CI/CD platforms that scale. Pipeline templates prevent every team from rebuilding the same stages independently and allow platform teams to propagate improvements across the entire organization when a new best practice is established.
Platform engineering creates the internal developer platform (IDP) that product teams deploy through rather than against. Pipeline templates cover the standard build, test, security, and deployment stages. Teams configure what is specific to their service without rebuilding the foundation. When a security gate needs to be updated across the organization, the platform team updates the template and the improvement propagates automatically to every pipeline that uses it.
For engineering organizations with multiple product teams, multiple repos, and developers spread across offices in Hyderabad, Pune, Bengaluru, Austin, or Dubai, this kind of centralized platform governance is what prevents the divergence that makes the engineering organization impossible to observe as a whole.
Our blog on Internal Developer Platform: How Platform Engineering Improves Developer Productivity covers how the IDP layer connects to pipeline performance in detail.
P99Soft's Platform Engineering and Backstage Consulting practices build exactly this layer, including the service catalogues, deployment templates, and golden paths that let product teams ship without needing to understand the infrastructure underneath.
Best Practice 5: Environment Parity Eliminates the Most Common Class of Deployment Failure
If staging and production are not genuinely identical, every deployment carries a category of risk that testing cannot catch. The application works in staging because staging is configured slightly differently from production — a different database version, a different environment variable structure, a different network topology. The failure appears in production and is attributed to bad code when it should be attributed to environment divergence.
Infrastructure as code closes this gap by making every environment a repeatable artifact. Terraform or Pulumi definitions checked into version control and applied through the CI/CD pipeline ensure that staging, production, and any environment in between are created from the same specification. Manual configuration drift becomes impossible because there is no manual configuration.
For Bare-Metal Provisioning Consulting engagements, where teams need cloud-like automation and environment consistency on physical infrastructure, this same principle applies through automated provisioning workflows that treat bare-metal servers with the same repeatability as cloud virtual machines.
Ephemeral test environments extend this further. Rather than maintaining a permanent staging environment that drifts from production over time, teams can provision fresh environments for each feature branch, run integration tests against a clean environment that exactly matches production, and tear it down when the tests complete. The environment cost is small. The reliability improvement is significant.
Best Practice 6: DORA Metrics Are the Diagnostic Tool, Not Just the Report
The four DORA metrics, deployment frequency, lead time for changes, change failure rate, and mean time to recover, are the most useful diagnostic framework available for enterprise CI/CD performance. But they are only useful if they are tracked continuously and acted on, not compiled quarterly for a leadership presentation.
Deployment frequency tells you how often code reaches production. Elite teams deploy multiple times per day. If your team deploys once per week, the constraint is almost never technical. It is a process gate, an approval step, or a fear of deployment that reflects something cultural rather than something architectural.
Lead time for changes measures the journey from code commit to production deployment. Elite teams achieve this in under one hour. If your lead time is measured in days or weeks, the pipeline is not the primary bottleneck. Testing, review cycles, and environment provisioning are more likely candidates.
Change failure rate measures the percentage of deployments that cause a production incident requiring a fix or rollback. Elite teams keep this below fifteen percent. If yours is higher, the test coverage or staging environment gap is likely the cause.
Mean time to recover measures how quickly the team restores service after a production incident. This is largely a function of observability quality and rollback automation. Teams that have invested in both recover in minutes. Teams that rely on manual diagnosis and manual rollback procedures recover in hours.
These four numbers together create a diagnostic picture that tells engineering leadership exactly which layer of the delivery system to invest in next. They are not metrics to optimize. They are signals to understand.
For a full explanation of how these metrics apply to pipeline architecture decisions, our blog on What is DevOps Continuous Delivery? CI CD Pipeline Explained for Modern Software Teams covers the conceptual foundation.
CI/CD Optimization for Distributed Teams: India-Specific Considerations
Engineering organizations with delivery centers in India operating alongside product owners and customers in North America or Europe face a specific version of the pipeline performance problem. Decisions that cross time zones cost more than decisions that stay within one.
A pull request that opens at 4pm IST and waits two hours for a CI result has missed the US morning. A deployment that requires a manual approval from a US-based product owner cannot happen during Indian working hours unless that approval process is either automated or the approval authority is distributed to the team closest to the code.
Four specific optimizations matter most for distributed teams:
Autonomous deployment authority. Teams that can deploy to production without waiting for cross-timezone approval deploy faster and with better outcomes. Progressive delivery makes this safe because the risk of a deployment is contained by the canary percentage, not by the approval chain. Build confidence in the technical controls, then reduce the approval overhead.
Pipeline notifications that match working hours. A failed build notification that arrives at 2am IST will not be acted on until the next morning, which means the developer who pushed the code has already moved on to something else. Routing pipeline notifications to the team in the timezone where it is working hours preserves the context connection between the failure and the fix.
Parallel environments for parallel time zones. When an engineering team in Hyderabad is testing while a team in Austin is building, they should not be sharing the same staging environment. Ephemeral environments provisioned per feature branch or per team prevent interference and allow both groups to validate their work without coordination overhead.
Build caching that persists across working hours. A cache that expires after eight hours will not help a developer in Pune whose work builds on cache artifacts created during US working hours. Cache TTL configuration should account for the full 24-hour development cycle of a globally distributed team, not just a single eight-hour shift.
How P99soft Approaches CI/CD Pipeline Optimization
P99Soft's Platform Engineering Excellence practice approaches CI/CD optimization as a full-stack engineering problem, not a tooling selection exercise. The work begins with a pipeline audit that produces a performance baseline: build times by stage, test reliability metrics, security gate placement, deployment frequency, and the DORA metrics that describe the pipeline's current delivery capability.
From that baseline, optimization work proceeds in the sequence that produces the fastest measurable improvement. Build speed and parallel execution come first because they affect every developer every day. Security gate redesign ensures compliance requirements do not add unnecessary latency. Progressive delivery implementation removes deployment fear and enables more frequent releases. Platform engineering and Backstage integration make the improvements sustainable as the team grows.
Our Backstage Consulting work builds the developer portal layer that makes pipeline templates, service catalogues, and self-service deployment accessible to every product team without requiring them to understand the platform engineering decisions underneath.
FAQ
What is CI/CD pipeline optimization and why does it matter for enterprises?
CI/CD pipeline optimization is the process of improving the speed, reliability, security, and governance of the automated workflow that takes code from a developer's commit through build, testing, and deployment to production. It matters for enterprises because slow pipelines reduce developer productivity, increase context-switching costs, and slow the organization's ability to respond to market changes. Enterprise teams in India and globally are increasingly measured by delivery frequency and lead time, both of which are direct functions of pipeline performance.
What are the most impactful CI/CD optimizations for enterprise teams?
The most impactful optimizations are parallel job execution to reduce build time, dependency caching to eliminate redundant package downloads, selective test execution on pull requests, security gates built into the pipeline at the correct stage rather than appended at the end, and progressive delivery strategies that separate deployment from release. Addressing all five typically reduces total pipeline time by 60 to 80 percent and reduces change failure rates to below fifteen percent.
How does progressive delivery reduce deployment risk?
Progressive delivery separates the act of deploying code from the act of releasing it to users. Code is deployed to production in a dormant state using feature flags, then released to a small percentage of users first, typically one to ten percent. If the release produces elevated error rates or degraded performance, the feature flag is turned off in seconds and no rollback deployment is required. This approach means issues are caught when they affect one percent of users rather than one hundred percent, and recovery takes seconds rather than hours.
What CI/CD challenges are specific to engineering teams in India working with global clients?
The main challenges are time zone gaps that turn pipeline feedback delays into next-day blockers, cross-timezone approval dependencies that prevent autonomous deployment, shared staging environments that create interference between teams working different hours, and cache configurations that do not account for 24-hour development cycles. These challenges are best addressed by distributing deployment authority to the team closest to the code, using ephemeral environments that do not require sharing, and configuring pipeline notifications to route to the active timezone rather than a fixed channel.