Legacy Modernization: How to Move From Monolith to Microservices Without Breaking Your Business

At some point, almost every engineering organization hits the same wall. A feature that should take two weeks takes six. A bug in the payment service requires a full application redeploy. A team in one part of the codebase cannot release without coordinating with three other teams. The system still works, but it is actively slowing the business down.
The usual conclusion is "we need to move to microservices." Sometimes that conclusion is correct. Often it is not. And the gap between those two outcomes is exactly where the most expensive legacy modernization mistakes happen.
This guide covers what to consider before starting, which migration patterns actually work in production, and how to move from a monolith to microservices without creating a new class of problems in place of the original ones.
What Is a Monolith and When Does It Become a Problem
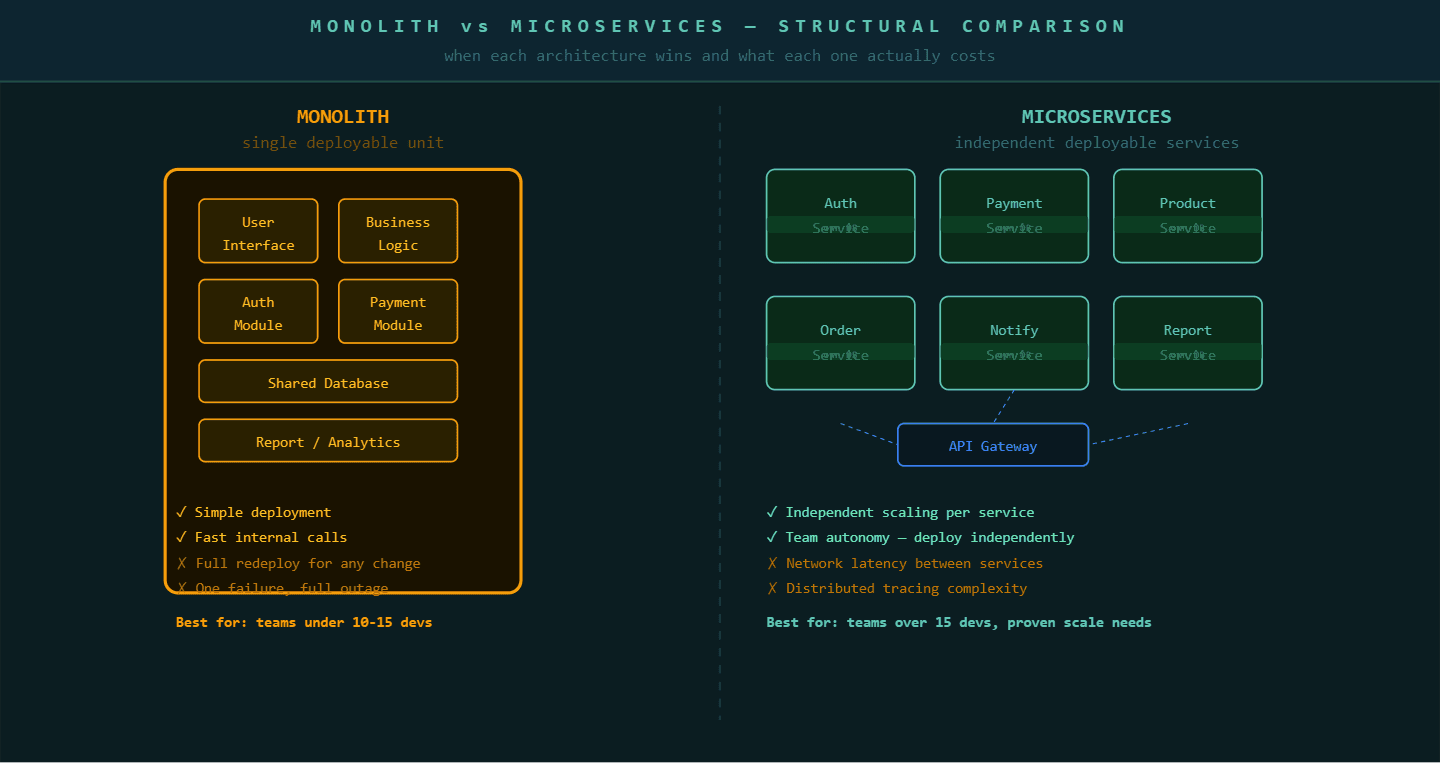
A monolith is a legacy software architecture where an entire application runs as a single deployable unit, meaning all business logic, data access, and user interface code are compiled and deployed together.
Monoliths are not inherently bad. Research shows that microservices benefits only materialize with teams exceeding 10 to 15 developers and proven independent scaling needs. Below that threshold, a monolith is frequently the faster, cheaper, and more reliable architecture. The deployment simplicity, the shared memory for function calls instead of network calls, and the absence of distributed system complexity give small teams a genuine productivity advantage.
A monolith becomes a problem when four specific things start happening. First, the deployment cycle becomes a coordination exercise involving multiple teams. Second, a failure in one module takes down the entire application. Third, one part of the system has significantly higher traffic than the rest and you cannot scale it independently. Fourth, technology choices made years ago are now blocking new development and you cannot replace one piece without rewriting everything.
When these four signals appear together, legacy modernization is not optional. It is a structural requirement.
The decision to move from monolith to microservices should be driven by specific operational constraints, not architectural ideology. Document the constraint first, then select the architecture.
Why Most Monolith to Microservices Migrations Fail Midway
Most monolith to microservices migrations fail because teams treat it as a one-time project rather than an incremental transformation.
The typical failure pattern looks like this. An organization decides to migrate. They spend three to six months planning the full target architecture. They attempt to extract five to eight services simultaneously. The dependency graph between those services turns out to be more complex than the planning phase revealed. The migration stalls at 40 percent complete. The team ends up maintaining a partial monolith and a partial microservices environment, which carries all the operational complexity of both with the benefits of neither.
According to DORA metrics research, 90% of microservices teams still batch deploy like monoliths, achieving maximum complexity with minimum benefit. This statistic reveals the root cause of most migration failures: teams change the architecture without changing the delivery culture. The microservices are there. The organizational and operational practices needed to benefit from them are not.
The cloud microservices market was projected to grow from $2 billion in 2025 to $5.61 billion by 2030, reflecting the scale of investment happening across the industry. But investment in the architecture does not guarantee investment in the practices needed to make it work. The teams that benefit most from microservices are those that arrive at the architecture incrementally, service by service, with each extracted service fully operational and owned before the next one begins.
The Strangler Fig Pattern: The Safest Migration Path
The strangler fig pattern is the most reliable approach to moving from a monolith to microservices without disrupting production operations.
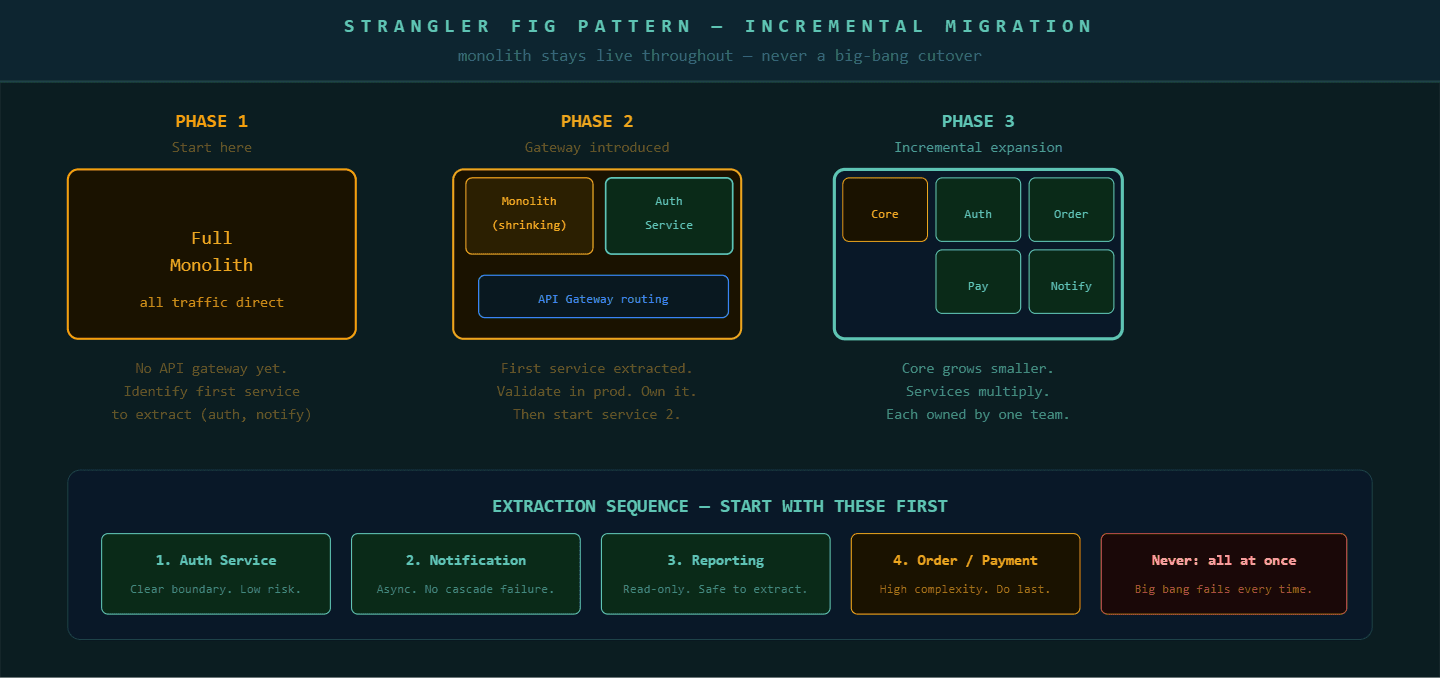
The strangler fig pattern (named after a tree that grows around an existing tree, gradually replacing it) works by building new functionality as standalone microservices from the start, while simultaneously extracting existing functionality from the monolith piece by piece. An API gateway (a routing layer that sits in front of your application and directs incoming requests to the correct service) sits between users and the application. It routes specific request types to newly built microservices while the rest continue hitting the monolith.
This approach produces three specific advantages. First, the monolith continues running in production throughout the migration, so business operations never depend on the migration completing. Second, each extracted service goes through a full production validation cycle before the next extraction begins. Third, the team builds operational competency, monitoring, deployment automation, and inter-service communication, service by service rather than all at once.
The practical sequencing follows a consistent pattern. Start with the services that have the clearest, most independent boundaries and the highest independent scaling needs. Authentication services, notification services, and reporting services are common starting points because their inputs and outputs are well-defined and their failure does not cascade through the entire application.
Database Decomposition: The Hardest Part Nobody Plans For
Database decomposition is the step that most teams underestimate and the step that most often stalls a migration.
In a monolith, all services share a single database. When you extract a service into a standalone microservice, that service needs its own database. Breaking a shared database apart is significantly more complex than breaking apart the application code. Foreign key relationships that existed inside the database now need to become API calls between services. Data that existed in one table now needs to exist in two places with synchronization logic between them.
The correct approach follows three stages. In the first stage, while still in the monolith, introduce logical separation within the shared database by giving each future service its own schema and eliminating cross-schema foreign key dependencies. In the second stage, run the extracted service against the shared database through a dedicated schema. In the third stage, physically migrate that schema to the service's own database instance. This three-stage approach makes each step reversible and observable, which big-bang database migrations are not.
Application modernization services work on exactly this problem. The application code refactor is straightforward compared to the database decomposition, and getting it wrong produces distributed data inconsistency that is expensive to resolve after the fact.
Kubernetes and Container Infrastructure for Microservices
Kubernetes is the container orchestration platform (a system that automates deployment, scaling, and management of containerized applications) that most microservices architectures run on.
Container-first deployment means each microservice is packaged as a Docker container, a standardized portable unit that includes the application and all its dependencies. Kubernetes manages those containers: scheduling them across servers, restarting failed containers, routing traffic between them, and scaling individual services up or down based on load.
The operational overhead of Kubernetes is real. It requires platform expertise, monitoring infrastructure, and a team that understands how to diagnose distributed system failures. This is one reason the microservices benefits threshold of 10 to 15 developers exists: below that size, the cost of maintaining Kubernetes exceeds the deployment flexibility it provides.
P99Soft's application modernization services cover the full migration lifecycle. That includes architecture assessment, extraction sequencing using the strangler fig pattern, database decomposition planning, Kubernetes cluster setup, and the observability infrastructure (monitoring, logging, and tracing systems) needed to operate microservices reliably in production. The goal is not a completed migration. It is a team that can operate, extend, and improve a microservices architecture without needing external help after the engagement ends.
The Migration Decision Framework: Should You Actually Do This
Not every monolith needs to become microservices. The decision should pass three tests before any migration work begins.
First, the scale test: do you have independent scaling requirements? If your search service runs at 100 times the traffic of your checkout service, microservices let you scale them independently. If your traffic profile is relatively uniform across modules, shared infrastructure scaling is cheaper and simpler.
Second, the team test: do you have more than 10 to 15 engineers actively working across the codebase? Below this threshold, the coordination overhead of microservices produces net productivity losses. Above it, independent team deployability becomes a genuine competitive advantage.
Third, the deployment test: is your current deployment cycle blocking feature delivery? If teams wait more than two weeks between the time code is written and the time it ships to users, and the blocker is deployment coordination rather than testing or review quality, microservices can solve the problem. If the blocker is something else, microservices will not fix it.
If all three tests pass, start the migration with the strangler fig pattern, one service at a time, with database decomposition planned before the first extraction begins.
The strangler fig pattern, incremental extraction with full production validation of each service before the next begins, is the safest proven path through a monolith to microservices migration.

FAQ
When should you migrate from monolith to microservices?
You should migrate from a monolith to microservices when your team exceeds 10 to 15 developers, you have proven independent scaling requirements where different modules carry significantly different traffic loads, and your deployment cycle is actively blocking feature delivery due to coordination overhead rather than code quality issues. If all three conditions are true together, the strangler fig migration pattern is the safest starting approach.
What is the strangler fig pattern in legacy modernization?
The strangler fig pattern is a migration strategy where you extract services from a monolith incrementally rather than rewriting everything at once. An API gateway routes specific requests to newly built microservices while the remaining functionality continues running on the monolith. Each extracted service goes through full production validation before the next extraction begins, keeping the business running throughout the migration.
Why do most monolith to microservices migrations fail?
Most migrations fail because teams attempt to extract multiple services simultaneously without validating each one in production first, and because they change the application architecture without changing the organizational practices needed to operate microservices. Research shows that 90 percent of microservices teams still batch deploy like monoliths, which means they carry the full operational complexity of microservices with none of the deployment independence benefits.
What is the hardest part of migrating from a monolith to microservices?
Database decomposition is consistently the hardest part of a monolith to microservices migration. Most monoliths share a single database with cross-table relationships that are easy to navigate inside one codebase but become expensive API calls between independent services. The correct approach introduces logical schema separation inside the shared database first, then physically migrates each schema to its own database instance after the service is running in production.
Modernizing legacy systems is not just a technical shift, it requires the right engineering approach and infrastructure decisions. If you are looking to build scalable systems alongside modernization, you can explore how software product engineering services enable long-term scalability and performance:
https://p99soft.com/blog/how-software-product-engineering-services-help-companies-build-scalable-products
From an implementation perspective, moving from monolith to microservices often involves adopting cloud-native architectures, optimizing workloads, and ensuring systems are built for scale from day one. Depending on your stage, you can explore:
Cloud-native product development for scalable system design
Serverless architecture solutions to reduce infrastructure overhead and improve agility
Legacy modernization services focused on transitioning from monolith to microservices
Kubernetes optimization to manage, scale, and improve performance of distributed systems
Each of these plays a critical role in ensuring that modernization efforts are not just successful at migration, but sustainable at scale.