How to Build a Data Architecture That AI Can Actually Use

There is a specific moment that almost every data leader recognizes. The AI pilot worked beautifully in a controlled environment. The model was accurate. The demos impressed the board. Then someone tried to run it against real production data and it started producing answers that were inconsistent, unexplainable, or just wrong. The model got blamed. The data team defended themselves. The budget got questioned.
The model was not the problem. The architecture underneath it was.
Sixty-five percent of organizations have already deployed generative AI in some form. Most of them are stuck at the pilot stage. The constraint is almost never the AI capability itself. It is the state of the data infrastructure the model has to work with. According to IBM research, up to 90 percent of enterprise data sits locked in unstructured silos, missing the unified semantic layer that AI needs to generate reliable outputs at scale.
This is a solvable architecture problem. But solving it requires understanding what AI-ready data infrastructure actually looks like, layer by layer, before a single model is trained or a single pipeline is retrofitted.
Why Most Enterprise Data Architectures Were Not Built for AI
Most enterprise data architectures were built to answer questions about the past, not to power systems that act in the present.
Traditional data warehouses, built over the last decade and a half, were designed for business intelligence: structured data, batch processing, and periodic reporting. They answered questions like "how did we perform last quarter?" very well. They were not designed to answer questions like "what should this customer see right now?" or "which supplier is most likely to miss the next shipment?" in real time.
AI requires something fundamentally different from a BI reporting layer. AI models need access to both structured data, the clean rows and columns in a warehouse, and unstructured data, documents, emails, sensor readings, images, and logs, all from a single place. They need metadata that explains what each dataset means and who owns it. They need data that is fresh enough to be relevant, not batch-refreshed from 48 hours ago. And they need all of this to be governed tightly enough that the outputs can be explained, audited, and trusted by the people who act on them.
Building that capability on top of a legacy data warehouse is like building a highway on a footpath. The underlying structure was designed for a different purpose entirely.
The reason most AI pilots stall is not model quality. It is that the data architecture underneath was designed for reporting, not for inference. Fixing the model without fixing the architecture produces the same failure at higher speed.
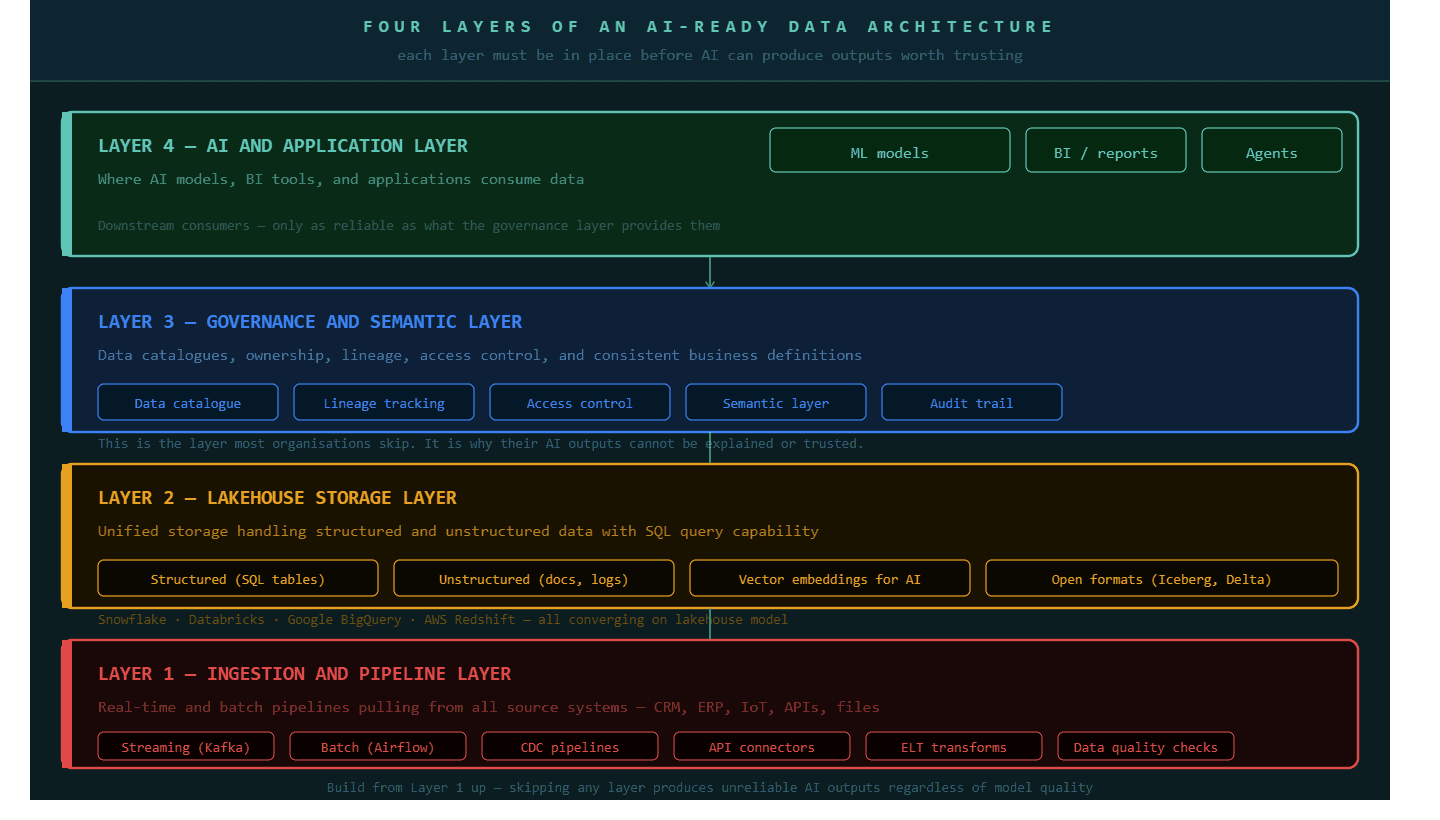
Layer 1: The Ingestion and Pipeline Layer — Where Data Enters the Architecture
A reliable data pipeline is the foundation that every other AI-ready layer depends on, and most organizations discover their pipelines were built for yesterday's workload when they try to run AI on today's data.
Data pipelines are the systems that move data from source systems, your CRM, your ERP, your IoT sensors, your third-party APIs, your transaction logs, into a central storage environment. In a traditional architecture, most of this movement happened in batch: once a day, once an hour, or once a week. The data was always slightly stale, but for reporting purposes that was acceptable. For AI, it often is not.
The shift that matters most at the ingestion layer is moving from batch-first to event-first design. Event-driven pipelines, where data flows continuously as events happen rather than on a schedule, use technologies like Apache Kafka, a distributed streaming platform, to ensure that the data feeding your AI models reflects what is happening now rather than what happened yesterday. This matters enormously for use cases like fraud detection, demand forecasting, personalization, and supply chain intelligence, where the value of a prediction degrades rapidly if the underlying data is hours old.
The ingestion layer also needs to handle data quality at the point of entry rather than treating quality as a downstream concern. Every pipeline should include schema validation, null-value detection, and duplicate filtering before data reaches the storage layer. Data that enters the architecture clean is exponentially cheaper to maintain than data that is cleaned retrospectively after AI models have already learned from it.
A strong ELT pattern, where data is extracted from source systems, loaded into the central storage layer in its raw form, and then transformed inside that layer rather than before loading, gives the architecture flexibility that ETL (extract, transform, load) does not. With ELT, the raw data is always available and transformations can be changed without re-running the original ingestion. For AI, this means models can be retrained on differently structured views of the same underlying data without re-architecting the pipeline.
Layer 2: The Lakehouse — The Storage Architecture AI Actually Needs
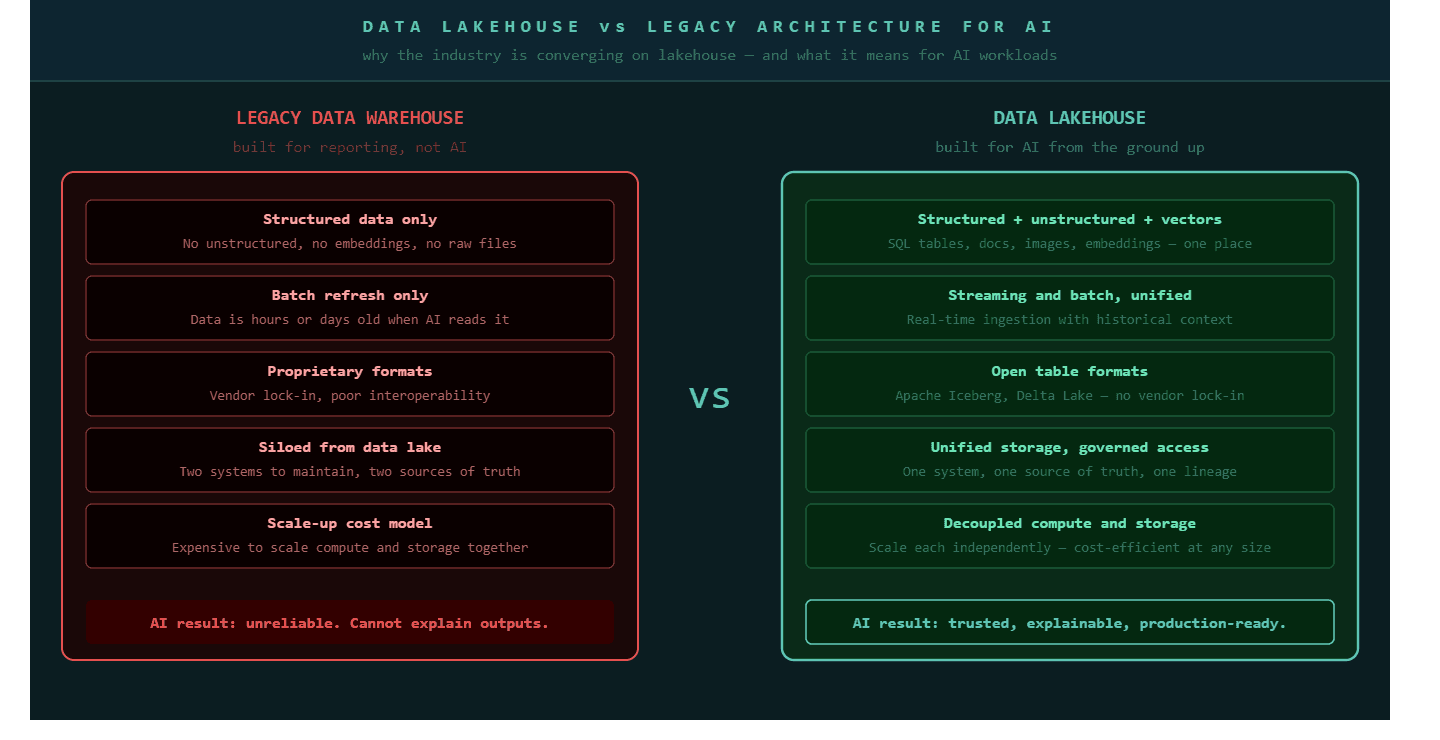
A data lakehouse is a hybrid storage architecture that combines the flexibility of a data lake with the structure and query performance of a data warehouse, and it is becoming the default foundation for AI-ready enterprise data infrastructure.
Traditional data warehouses stored clean, structured data in relational tables. They answered SQL queries quickly and predictably. Data lakes stored everything, structured tables, semi-structured JSON, unstructured documents, images, and log files, without imposing a schema. The problem with data lakes was that without structure, finding and using data reliably was difficult. The problem with data warehouses was that the enormous volume of unstructured data that modern businesses generate could not live inside them effectively.
The lakehouse solves both problems. It stores raw and processed data together in open formats like Apache Iceberg or Delta Lake. These formats support ACID transactions, which means changes to data are reliable and traceable, the same property that makes relational databases trustworthy. They support SQL queries across structured data. And they support the storage of vector embeddings, the numerical representations that AI models use to understand text, images, and other unstructured content.
Snowflake, Databricks, and Google BigQuery have each converged on the lakehouse model. The global spending on big data and analytics reached $420 billion in 2026, and the majority of that investment is flowing toward lakehouse infrastructure. The reason is practical: organizations that try to run AI on a pure data lake struggle with reliability. Organizations that try to run AI on a pure warehouse struggle with unstructured data. The lakehouse handles both.
For organizations currently running a legacy data warehouse, the migration path does not require a full replacement. A common approach is to introduce a lakehouse layer alongside the existing warehouse, routing new data types and AI workloads to the lakehouse while allowing the warehouse to continue serving established reporting needs. Over time, the warehouse responsibilities consolidate into the lakehouse, and the architecture simplifies rather than multiplies.
The lakehouse is not a trend. It is the storage architecture that handles the full range of data types that AI models need. Organizations that delay adopting it are building AI on a foundation that cannot support the data variety modern models require.
Layer 3: The Governance and Semantic Layer — Where Architecture Becomes Trustworthy
Data governance is the prerequisite for AI at scale, not the afterthought that gets addressed after something goes wrong.
A governance layer is the system of policies, tools, and processes that defines what each piece of data means, who owns it, who can access it, how it was created, and how it connects to other data in the architecture. Without this layer, an AI model can produce an output that is technically derived from real data and still be fundamentally misleading because the data it drew from was inconsistently defined across source systems.
Consider a business that defines "active customer" differently in its CRM than in its billing system. An AI model trained on both will produce inconsistent outputs depending on which system's data dominates in a given inference. The model is not wrong. The data is ambiguous. And the governance layer is what prevents that ambiguity from entering the architecture in the first place.
The governance layer has five practical components that every AI-ready architecture requires.
A data catalogue is the searchable inventory of every dataset in the architecture, what it contains, where it came from, who maintains it, and what it is used for. Without a catalogue, data teams spend a significant portion of their time locating data rather than using it.
Data lineage tracking records the full journey of every data point from its source system through every transformation to its final use in a model or dashboard. When an AI output is questioned, lineage is what allows an engineer to trace the output back to its origin and identify exactly where a quality issue entered.
A semantic layer translates raw data fields into consistent business definitions. Revenue is revenue. An active customer is an active customer. The same definition applies whether the query comes from a BI tool, a data scientist's notebook, or an AI agent. Without a semantic layer, different consumers of the same data arrive at different answers to the same question.
Access controls define who can query which datasets, at what level of detail, and under what conditions. For AI specifically, this matters because models trained on data that certain users should not see can inadvertently expose sensitive information through their outputs.
Audit trails record every access, transformation, and model inference tied to governed data. For regulated industries and for any organization that will need to explain its AI decisions to a board, regulator, or customer, audit trails are not optional.
Governance is not a compliance activity. It is the infrastructure that makes AI outputs trustworthy enough to act on. Organizations that deploy governance after AI, rather than before it, spend most of their time explaining why the model said what it said.
Layer 4: Integration, Connecting the Architecture to Where Decisions Happen
An AI-ready data architecture is only valuable if it connects to the systems where the outputs actually change something.
Data integration for AI is the discipline of building the connections between your central data platform and the operational systems where decisions get made. Sales representatives who use a CRM. Operations managers who use a supply chain tool. Customer service teams who use a ticketing platform. If the AI insights generated by your data architecture cannot reach these people in the tools they use daily, the architecture produces reports that get read and forgotten rather than intelligence that changes how work gets done.
The integration layer typically involves three types of connections. API integrations push AI outputs from the data platform into operational systems in real time. A demand forecast generated at 6am should appear in the procurement team's planning tool by 7am, not in a dashboard they check when they remember to. Embedded analytics integrations bring BI visualizations directly into operational workflows rather than requiring users to navigate to a separate analytics portal. Model serving infrastructure makes the AI model itself available as an API that operational applications can query in real time, returning a prediction or recommendation within milliseconds as part of a normal workflow.
This is where strategic data consulting becomes most valuable. The architecture decisions at the integration layer depend on a clear understanding of how each business function actually makes decisions, which systems those decisions happen in, and what format AI output needs to take to be actionable rather than informational. Getting this wrong produces technically correct AI outputs that no one uses because they do not fit naturally into existing work patterns.
P99Soft's data and AI practice works across all four of these layers. Our big data architecture and infrastructure work designs the ingestion and lakehouse layers. Our data warehousing and integration practice handles the migration from legacy architectures and the build of integration pipelines. Our strategic data consulting engagements define the governance framework and the integration roadmap before any architecture work begins. And our data governance and security practice builds the semantic and access control layers that make AI outputs trustworthy enough to deploy at scale.
The goal of every engagement is the same: a data architecture that an AI model can use without producing outputs you have to apologize for.
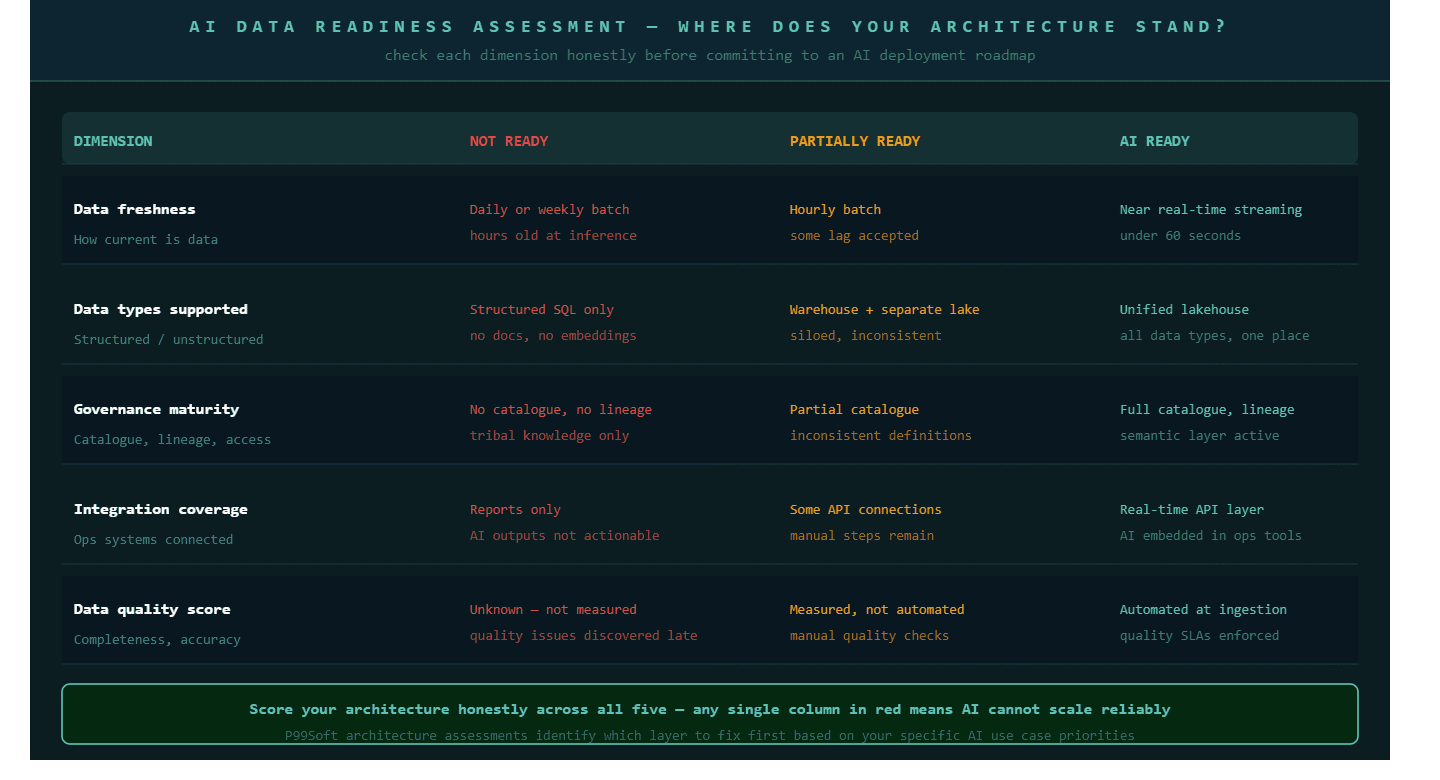
How to Sequence the Build: What to Fix First
The sequencing of an AI data architecture build matters as much as the architecture itself. Organizations that try to build all four layers simultaneously almost always end up with an incomplete version of each, which produces a system that is technically more complex than what they started with and no better at supporting AI workloads.
The correct sequence follows a simple dependency chain.
Start with data quality at the ingestion layer. Before investing in a lakehouse migration or a governance framework, run an honest audit of the data flowing into your architecture today. Identify the three to five datasets that your AI use cases depend on most heavily and assess their completeness, accuracy, and freshness. This audit typically reveals that 20 to 30 percent of the data quality problems come from a small number of broken or poorly designed ingestion pipelines. Fixing those pipelines first costs far less than discovering the same issues after they have contaminated a newly built lakehouse.
Move next to the storage migration. If you are running a legacy data warehouse, the lakehouse migration does not require a full cutover. Introduce the lakehouse layer for new AI workloads and new data types while the existing warehouse continues to serve established BI reports. This parallel running period, typically three to six months, lets the team build lakehouse competency without disrupting production reporting.
Build the governance layer in parallel with the storage migration, not after it. Data catalogues, ownership assignments, and semantic layer definitions take time to establish. Starting this work while the storage migration is underway means the governance infrastructure is ready when data begins flowing into the new architecture, rather than being retrofitted after data quality problems surface in AI outputs.
Finally, build the integration layer once the first three layers are stable. Connecting AI outputs to operational systems before the underlying architecture is reliable creates operational dependencies on unreliable outputs, which is harder to remove than it is to avoid.
FAQ
What is AI-ready data architecture?
An AI-ready data architecture is a data infrastructure designed to give AI models consistent, high-quality, and well-governed access to the full range of data an organization generates. It typically includes four layers: a real-time data ingestion and pipeline layer, a unified lakehouse storage layer that handles both structured and unstructured data, a governance and semantic layer that ensures data quality and consistency, and an integration layer that connects AI outputs to the operational systems where decisions get made.
Why do most AI projects fail to reach production?
Most AI projects fail to reach production because the data infrastructure beneath them was not built to support AI workloads. The model produces inconsistent or unexplainable outputs because the data it trained on was siloed, inconsistently defined, or stale. According to IBM research, up to 90 percent of enterprise data sits in unstructured silos without the unified semantic layer that AI needs to generate reliable outputs at scale. Fixing the data architecture, not the model, is almost always the correct intervention.
What is a data lakehouse and why does AI need it?
A data lakehouse is a hybrid storage architecture that combines the flexibility of a data lake, which stores structured and unstructured data in any format, with the performance and reliability of a data warehouse, which supports SQL queries and ACID transactions. AI needs a lakehouse because modern AI models require access to both structured data, such as customer records and transaction tables, and unstructured data, such as documents, emails, images, and sensor readings, from a single consistent storage layer with open formats that any tool or model can read.
What is a semantic layer in data architecture? A semantic layer is a governance and translation layer that sits between raw data storage and the applications or AI models that consume data. It translates raw database fields into consistent business definitions. Revenue means the same thing whether the query comes from a BI dashboard, a data scientist's notebook, or an AI agent. Without a semantic layer, different consumers of the same data arrive at different answers to the same business question. For AI, the semantic layer is what ensures that model outputs reflect shared business logic rather than the quirks of individual source systems.