Data Governance Is Not a Compliance Exercise. It Is What Separates Useful AI From Expensive AI.

Here is a scenario that plays out more often than most data leaders want to admit.
A company runs a pilot for an AI-powered customer churn model. The results look strong. The model goes to a broader stakeholder review. Someone asks which data the model was trained on. Someone else asks whether the "churn" definition used matches the one in the finance system. A third person points out that the CRM data was cleaned differently last quarter than the quarter before. The review stalls. The model sits in limbo. Three months later, the initiative is quietly deprioritized.
The model was not bad. The data underneath it was ungoverned.
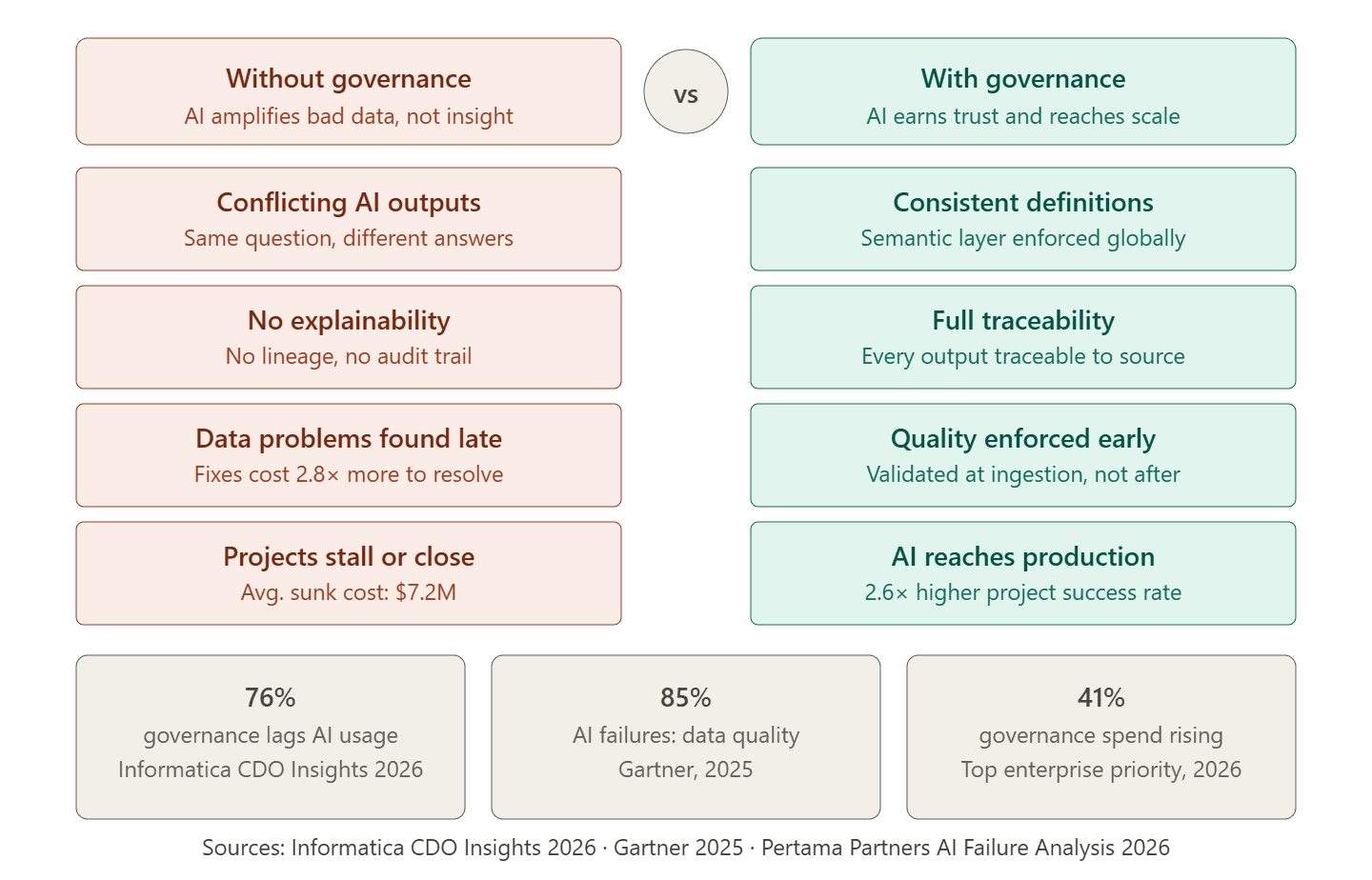
Gartner reports that 85% of AI projects fail due to poor data quality or lack of relevant data. In 2025, 42% of companies abandoned at least one AI initiative, with the average sunk cost per abandoned project reaching $7.2 million. The pattern these numbers describe is consistent: organizations invest in AI capability without first investing in the data foundation that AI requires to work reliably. Governance is what builds that foundation, and most organizations are treating it as an afterthought.
What Data Governance for AI Actually Means
Data governance for AI is not the same thing as data governance for compliance, though the two overlap.
Compliance governance asks: does this data handling meet regulatory requirements? It is backward-looking. It is about demonstrating that what happened was permitted. For regulated industries, this matters enormously. But it is not sufficient for AI.
AI governance asks: can this data be trusted to produce outputs we can act on and explain? It is forward-looking. It is about ensuring that what the model learns, infers, and recommends reflects reality consistently enough to be useful.
The practical difference shows up in one specific scenario. A compliance-governed organization can demonstrate that customer data was handled according to GDPR. That same organization can still have a customer analytics model that produces contradictory recommendations depending on which day the query runs, because the data feeding the model is defined differently in three source systems. No regulation was broken. The AI output is still unreliable.
According to Informatica's CDO Insights 2026 study of 600 global data leaders, 76% report that AI governance does not fully keep pace with employee usage, increasing risks around privacy, security, ethics, and regulatory compliance. That is not a niche problem. It is the majority condition.
Compliance governance and AI governance have different objectives. Meeting regulatory requirements does not automatically produce AI-ready data. Governance for AI requires consistency, lineage, ownership, and quality controls that are enforced at the infrastructure level, not reviewed after the fact.
Why AI Makes Bad Data Worse, Not Better
There is a widely held assumption that AI can clean up messy data as it processes it. This assumption is one of the most expensive beliefs in enterprise technology right now.
AI models do not correct data quality problems. They learn from them. A model trained on inconsistently labelled customer records does not figure out the correct labels. It learns the inconsistency as a pattern and reproduces it at inference time, at scale, faster than any human analyst could. Bad data going into a model does not come out as good outputs with a confidence score attached. It comes out as wrong outputs that look like good outputs because the model is confident in what it learned.
Publicis Sapient's 2026 Guide to Next report is direct about this: "AI projects rarely fail because of bad models. They fail because the data feeding them is inconsistent and fragmented."
The organizations that have learned this lesson the hard way share a common remediation story. They spent months improving their model, tuning hyperparameters, experimenting with different architectures. The outputs did not meaningfully improve. Then they spent three weeks resolving a data definition conflict between two source systems and fixing a pipeline that had been introducing null values since a schema change six months prior. The model's performance improved significantly within two weeks of the data work.
The model was never the problem. It was doing exactly what it was built to do: find patterns in the data it was given.
The Five Components That Make Data Governance Work for AI
Most organizations that describe themselves as having data governance have pieces of it. They have a data catalogue that was built two years ago and is now partially out of date. They have access controls that were designed for reporting workloads and have not been updated for AI inference patterns. They have data quality rules that run after data loads rather than at ingestion.
Governance that works for AI has five specific components that need to be present and connected to each other.
Data ownership with real accountability. Every dataset that feeds an AI model needs a named owner who is responsible for its quality, its currency, and its definition. Not a team. A person. When a data quality issue surfaces in an AI output, ownership determines how fast it gets resolved. Without it, the investigation becomes a committee exercise.
Consistent business definitions enforced at the infrastructure level. The semantic layer, meaning the translation layer that maps raw database fields to agreed business definitions, is where most governance programs fall short. Revenue needs to mean the same thing in the model as it means in the finance report. Churn needs to be defined consistently whether the query comes from a data scientist's notebook, a BI dashboard, or an AI agent. This agreement cannot live in a wiki. It needs to be enforced in the data infrastructure itself.
End-to-end data lineage. Lineage is the record of where every data point came from, what transformations it passed through, and where it ended up. For AI specifically, lineage is what allows an engineer to trace an unexpected model output back to its source and identify exactly where the quality issue or definition mismatch entered. Without lineage, troubleshooting AI outputs is guesswork.
Data quality validation at ingestion, not after. Quality checks that run at the point where data enters the architecture are orders of magnitude cheaper than quality checks that run after a model has trained on months of corrupted data. Null detection, schema validation, range checks, and duplicate filtering belong in the pipeline, not in a post-processing audit.
Access controls designed for AI workload patterns. AI models query data at scales and with access patterns that differ significantly from human analysts. Access controls built for a reporting environment often fail to account for model training jobs that scan full tables, inference pipelines that need low-latency reads, or agentic AI systems that make autonomous queries against multiple datasets. Governance frameworks need to be updated for these patterns before AI workloads go live, not after.
Data governance for AI is not a single tool or a single policy document. It is five interconnected capabilities that need to be operational before AI models go to production. Any one of them missing creates a class of failure that the model cannot compensate for.
What Happens When Governance Scales With AI Adoption
Informatica's CDO Insights 2026 study found that enhancing data and AI governance was the second biggest data management spending driver for enterprises in 2026, cited by 41% of the 600 global data leaders surveyed. That is a meaningful shift. Governance used to be the budget line that got cut when the AI project budget ran short. It is now being recognized as the reason AI projects either work at scale or do not.
Gartner predicts 40% of agentic AI projects will be canceled by 2027 due to governance failures. Agentic AI, meaning AI systems that take autonomous actions rather than just generating text or making predictions, is the direction the entire industry is moving. These systems make decisions. They execute processes. They write and run code. The governance requirements for systems that act autonomously are significantly higher than for systems that recommend. Organizations building agentic AI on an ungoverned data foundation are building the most consequential class of AI on the least reliable data infrastructure.
The organizations that consistently move AI from pilot to production share a specific practice: they run a data governance readiness assessment before committing to any AI use case. That assessment identifies which datasets the use case requires, whether those datasets have clear ownership and consistent definitions, whether the pipelines delivering them meet the freshness and quality requirements of AI inference, and whether access controls are appropriate for how the model will query the data. The assessment takes two to four weeks. It prevents the governance failures that cost $7.2 million per abandoned initiative on average.
How Governance Connects to Advanced Analytics and BI Quality
The connection between data governance and BI quality is direct and underappreciated.
Every executive dashboard, every pipeline report, every sales forecast that an analytics team produces is only as accurate as the data governance framework beneath it. When business users say they do not trust the numbers in the dashboard, they are almost always describing a governance failure, not a BI tool failure. The dashboard is showing what the data says. The data is inconsistently defined or poorly integrated. Governance is what fixes the data, which then fixes the dashboard.
For AI, this connection runs even deeper. Advanced analytics models trained on data that is not governed produce outputs that cannot be explained to the business stakeholders who need to act on them. A churn prediction that produces different scores for the same customer across two model runs is not a model problem. It is a data consistency problem. A demand forecast that nobody in procurement trusts is not a forecasting problem. It is a data ownership problem where nobody has been accountable for the quality of the input data.
P99Soft's data governance and security practice works with organizations to build governance frameworks that serve both BI quality and AI reliability simultaneously. Our strategic data consulting engagements start with an honest assessment of the current governance state across all five components, identify which gaps are most likely to cause AI failures, and build a sequenced roadmap that addresses those gaps before model work begins. The goal is not a governance framework that looks good in a presentation. It is governance infrastructure that makes AI outputs trustworthy enough for business decisions.
FAQ
What is data governance for AI and why does it matter?
Data governance for AI is the framework of ownership, quality standards, access controls, business definitions, and lineage tracking that ensures the data feeding AI models is consistent, reliable, and trustworthy. It matters because AI models do not correct data quality problems, they learn from them. A model trained on inconsistent or poorly governed data produces unreliable outputs regardless of how capable the model itself is. Gartner reports that 85% of AI project failures trace back to poor data quality or lack of relevant data.
What are data governance best practices for 2026?
The most important data governance practices for 2026 are: assigning named data owners with accountability for quality and definition, enforcing consistent business definitions through a semantic layer at the infrastructure level, building end-to-end lineage tracking that covers AI training and inference pipelines, validating data quality at ingestion rather than after the fact, and updating access controls to handle the query patterns of AI workloads rather than only human analytics workloads. Organizations that implement all five consistently report significantly higher AI project success rates.
How does data governance affect AI model performance?
Data governance directly determines the reliability and consistency of AI model outputs. When the data feeding a model is consistently defined, clean, and fresh, the model learns accurate patterns. When data is inconsistently defined across source systems, the model learns the inconsistency as a pattern and reproduces it at inference time. This is why troubleshooting AI outputs almost always leads back to a data problem rather than a model architecture problem.
What is the difference between data governance for compliance and data governance for AI?
Compliance governance focuses on demonstrating that data handling meets regulatory requirements and is primarily backward-looking. AI governance focuses on ensuring that data is consistent, accurate, and well-defined enough for AI models to produce outputs that can be trusted and explained. An organization can meet all relevant compliance requirements and still have ungoverned data that makes AI models unreliable. Both are necessary, but they have different objectives and require different controls.