Kubernetes Multi-Cluster Management: Why Single-Cluster Architectures Fail at Enterprise Scale and What to Do Instead

Kubernetes multi-cluster management becomes necessary when a single cluster can no longer satisfy the competing requirements of different teams, environments, regulatory boundaries, or geographic regions simultaneously. The four most common drivers of multi-cluster adoption are compliance isolation, regional latency requirements, team autonomy, and workload separation for AI and high-performance computing. Without a unified management plane across clusters, each cluster becomes a governance island with its own security configuration, its own access control model, and its own operational overhead.
Most organizations start with one Kubernetes cluster. This is correct. A single cluster is the right architecture when the workload is small, the team is small, and the compliance requirements are uniform. One cluster is easy to understand, easy to operate, and easy to secure.
By 2026, multi-cluster Kubernetes has become the operational baseline for organizations running globally distributed applications, navigating regulatory boundaries, or adopting hybrid and multi-cloud architectures. Clusters now span AWS, GCP, Azure, private data centers, and emerging edge environments, creating new layers of operational complexity.
The global Kubernetes market was valued at $2.57 billion in 2025 and is projected to reach $3.13 billion in 2026, growing at a 21.85% CAGR. 82% of organizations report using Kubernetes in production. Multi-cluster management is increasingly handled as a unified fleet-level challenge.
The problem is not that organizations choose multi-cluster architectures. The problem is that multi-cluster architectures happen to them before they have a strategy for managing them. The second cluster gets provisioned for a new environment. The third appears when a compliance requirement demands isolated infrastructure. The fourth and fifth emerge when two business units each need their own Kubernetes footprint. By the time the organization recognizes it has a multi-cluster management problem, they already have eight clusters managed eight different ways.
88% of teams report year-over-year TCO increases for Kubernetes according to the State of Production Kubernetes 2025 report, a challenge that becomes even more pronounced in multi-cluster public cloud environments.
That TCO increase is not intrinsic to multi-cluster architectures. It is the cost of multi-cluster architectures managed without a unified control plane. The same number of clusters managed through a platform like SUSE Rancher costs significantly less to operate than the same clusters managed individually, because the operational overhead per cluster drops from a full engineering practice to a configuration change.
Why Single-Cluster Architectures Break Down at Enterprise Scale
A single Kubernetes cluster serving the entire engineering organization works until one of four conditions becomes true. When any of them appears, the single-cluster model creates constraints that limit what the engineering organization can do.
Condition 1: Compliance isolation requirements. Financial services, healthcare, government, and defense organizations operate under regulatory frameworks that require certain workloads to be physically isolated from others. A hospital system cannot run a development environment and a clinical production system on the same cluster and satisfy HIPAA requirements for PHI isolation. A financial services firm cannot run cardholder data processing and general business applications on the same cluster and satisfy PCI DSS network segmentation requirements. These are not architectural preferences. They are compliance mandates that single-cluster architectures cannot satisfy regardless of namespace configuration.
The response to this constraint is almost always a second cluster, specifically provisioned to meet the isolation requirement. The problem is that this second cluster is frequently provisioned without the same security configuration, access control model, and operational practices as the first. The compliance-driven cluster was built differently by a different team at a different time, and maintaining consistency between them requires manual coordination that inevitably drifts.
Condition 2: Multi-team autonomy. Kubernetes clusters designed for shared use require coordination between teams for every change that affects the shared infrastructure. A team that wants to install a new cluster add-on, upgrade a shared dependency, or change network policy configuration must coordinate with every other team running on the same cluster. As team count grows, this coordination overhead grows faster than team count. A cluster serving 20 product teams requires a level of change management coordination that adds weeks to infrastructure decisions that should take hours.
Dedicated clusters per team or per business unit eliminate this coordination overhead at the cost of multiplying the number of clusters to manage. Without a unified management plane, the engineering cost of the coordination overhead reappears as the operational overhead of managing many clusters individually.
Condition 3: Geographic distribution and latency. Applications serving users across multiple regions require infrastructure deployed close to those users. A Kubernetes cluster running in a single AWS region serves users in that region with acceptable latency. Users in other regions experience the round-trip latency to the primary region for every request. Applications with strict latency requirements, real-time systems, financial trading platforms, and latency-sensitive user interfaces need clusters in the regions they serve.
Multi-region Kubernetes deployments introduce the full spectrum of distributed systems challenges: data consistency across regions, traffic routing that directs users to the nearest healthy cluster, and failure isolation that prevents a regional outage from affecting users in other regions.
Condition 4: Workload type isolation. AI and machine learning workloads running on GPU nodes have fundamentally different resource profiles, scheduling requirements, and security considerations from standard application workloads. GPU nodes are expensive. AI training jobs can consume entire nodes for hours or days. An AI training job that competes with production application workloads for node resources produces the kind of noisy neighbor problem that degrades both the training job and the production application.
As clusters proliferate and workloads grow, especially AI and ML workloads, TCO will attract greater scrutiny. Adoption of FinOps and cost visibility as part of cloud-native operations will gain more traction in 2026.
Separating AI workloads onto dedicated clusters with GPU node pools eliminates the resource contention, simplifies the security model for GPU access, and allows the AI infrastructure to be sized and scaled independently from application infrastructure.
Organizations do not choose multi-cluster architectures because they prefer complexity. They arrive at multi-cluster architectures because single clusters cannot simultaneously satisfy compliance isolation, team autonomy, geographic distribution, and workload type separation. The question is not whether to run multiple clusters. It is whether to manage them with a unified control plane or to manage each one individually.
What Happens Without a Unified Management Plane
The operational cost of managing multiple Kubernetes clusters without a unified management plane is not linear. It does not scale proportionally with the number of clusters. It compounds.
Every cluster managed individually requires its own access control configuration. When a new engineer joins the platform team, access must be granted on each cluster they need to reach. When an engineer leaves, access must be revoked from each cluster individually. Access audits require checking each cluster separately. A security policy change that applies to all clusters requires applying it to each cluster in turn, and the consistency of that application depends on whoever executes the process remembering to do it the same way on each one.
Enforcing consistent security posture, audit trails, and supply-chain guarantees across cloud and on-prem is hard, particularly when multiple vendor distributions and custom images are in play.
Every cluster managed individually runs its own upgrade cycle. A Kubernetes minor version release that needs to be applied to every cluster in the fleet requires 12 separate upgrade operations for a 12-cluster fleet, each requiring planning, validation, and rollback preparation. Without a unified upgrade orchestration layer, upgrade cadence inevitably falls behind, and clusters running different Kubernetes versions create compatibility issues for the tooling and workloads that span them.
Every cluster managed individually develops its own operational practices. The platform team that built cluster 3 configured monitoring differently from the team that built cluster 7. The network policy model on cluster 2 reflects decisions made in 2023 that have since been superseded. The access control model on cluster 5 uses a different group structure from every other cluster. These divergences are invisible until they matter, at which point they matter significantly.
Hybrid and multi-cloud strategies are in use by 63% or more of teams, with 85% overall cloud adoption. 67% of companies have delayed deployments due to Kubernetes security issues.
The deployment delays that security issues cause in multi-cluster environments are disproportionately attributable to the governance gaps that appear between individually managed clusters rather than to the security issues themselves. When an incident requires understanding what security policies are in effect across all clusters, individually managed clusters cannot answer that question quickly.
The Four Pillars of Enterprise Multi-Cluster Management
Managing multiple Kubernetes clusters as a coherent fleet rather than a collection of individual systems requires four operational capabilities working together.
Unified provisioning and configuration. Cluster provisioning through a central management plane applies a consistent configuration template to every new cluster. The networking driver, the storage class configuration, the initial RBAC setup, the monitoring integration, and the security policy baseline are defined once and applied consistently. A new cluster does not have a unique configuration history. It has the organization's standard configuration plus any legitimate environment-specific overrides that have been explicitly designed and reviewed.
SUSE Rancher's cluster provisioning model implements this through centrally defined cluster templates. A platform team that wants to provision a new development cluster selects the development cluster template and provides environment-specific parameters. Everything else, the networking configuration, the initial security policies, the monitoring setup, is inherited from the template rather than configured from scratch.
Centralized RBAC and identity. Multi-cluster access control managed from a single identity layer ensures that the access an engineer has been granted reflects the organization's current requirements rather than the historical accumulation of individually granted permissions. When a developer needs access to the staging cluster's frontend namespace and nothing else, that access is granted from the central management plane with explicit scope. When that access should be revoked, it is revoked from one place and takes effect everywhere.
Platform engineering adoption is expected to reach 80% in 2026. The platform engineering teams driving that adoption are building the identity and access control infrastructure that makes multi-cluster access manageable, rather than managing access through cluster-specific configurations that drift apart.
Fleet-level GitOps delivery. Configuration changes and workload deployments that need to apply across multiple clusters should flow through a GitOps system that manages the fleet as a unit rather than requiring per-cluster deployment operations.
SUSE Rancher's Fleet tool implements this for Rancher-managed clusters. The desired state of each cluster group is defined in a Git repository. Fleet continuously reconciles the deployed state of each cluster against the repository state. When a security policy needs to be updated across all production clusters, the update is made once in the repository and Fleet propagates it. When a new version of a platform add-on needs to be deployed across the fleet, the update is made in the repository and Fleet applies it in the order and timing specified by the rollout strategy.
GitOps adoption sits at 42%. Elite Kubernetes teams using GitOps deploy multiple times daily with low failure rates according to DORA benchmarks.
Unified observability and governance. A fleet of Kubernetes clusters without centralized visibility is a fleet where the security and operational health of each cluster is visible only to the team that manages that cluster. An engineering leader asking "what is the current security posture across all our clusters?" cannot get an answer without manual aggregation from each cluster's individual tooling.
A unified observability layer aggregates cluster health, security policy compliance status, resource utilization, and workload status from every cluster into a single interface. Compliance reporting that covers the full cluster fleet can be generated from that interface. Security incidents that appear as anomalies in one cluster can be investigated in the context of what is happening across the full fleet, which is often necessary for understanding whether an anomaly is isolated or a pattern.
SUSE Rancher as the Multi-Cluster Management Platform
SUSE Rancher addresses all four pillars of multi-cluster management from a single platform. The combination of Calico Enterprise from Tigera and SUSE Rancher Prime delivers a resilient and scalable platform that combines high-performance networking, robust network security, and operational simplicity in one stack.
Rancher's cluster provisioning handles the provisioning pillar through cluster templates and RKE2 or K3s as the Kubernetes distribution, providing consistent starting configurations for every environment. Rancher's centralized RBAC handles the identity pillar through organization-wide role definitions that propagate to every managed cluster. Rancher's Fleet handles the GitOps delivery pillar by managing fleet-wide configuration from Git repositories. Rancher's unified dashboard handles the observability pillar by aggregating cluster health and workload status from every managed cluster.
What makes Rancher specifically appropriate for multi-cluster environments with compliance requirements is the combination of RKE2's security hardening and Rancher's centralized policy enforcement. A new cluster provisioned from an RKE2 template starts in a known, compliant configuration. Rancher's centralized policy management ensures the cluster cannot drift from that configuration without a documented change going through the management plane.
P99Soft's SUSE Rancher Solutions practice designs the multi-cluster architecture that matches each organization's specific combination of compliance requirements, team structure, geographic distribution, and workload profile. The engagement covers cluster topology design, Fleet repository structure for GitOps-based fleet management, RBAC design across the full cluster fleet, and the integration with the security and delivery stack that makes the multi-cluster environment operationally coherent.
Designing the Right Multi-Cluster Topology
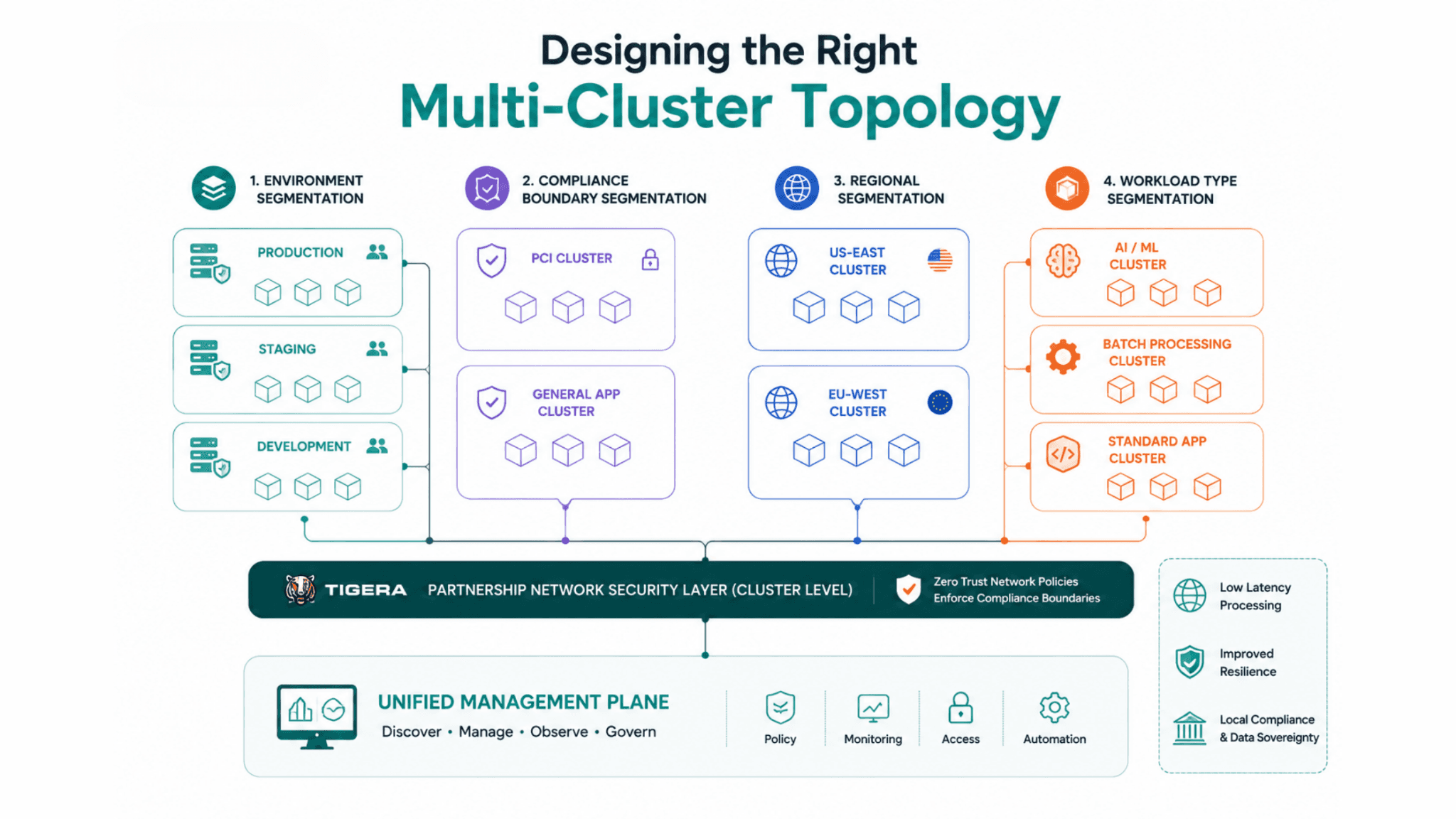
Multi-cluster topology design is where the abstract requirement for multiple clusters meets the concrete decisions about how many clusters to run, how to segment workloads between them, and how to structure the management plane.
The topology decisions that matter most for enterprise environments fall into four categories.
Environment segmentation. The minimum viable multi-cluster topology for most organizations separates production, staging, and development into distinct clusters. Production clusters are sized for production load, protected by production-grade security policies, and subject to change management processes. Staging clusters mirror production configuration but can tolerate updates and changes without business impact. Development clusters are lightly governed and change frequently. Each environment having its own cluster prevents the class of incident where a development activity affects production infrastructure.
Compliance boundary segmentation. Workloads subject to specific compliance frameworks run in dedicated clusters that are provisioned and governed specifically for those frameworks. A PCI-scoped cluster has network isolation, specific security policies, and compliance reporting configured to satisfy PCI DSS requirements from provisioning. A general application cluster that shares infrastructure with PCI-scoped workloads cannot satisfy the network segmentation requirements PCI DSS mandates.
Regional segmentation. Applications serving users in multiple geographic regions run in clusters provisioned in the regions they serve. The cluster topology reflects the latency requirements of the application: a real-time application serving European users from a US-East cluster is not meeting its users' expectations. Regional cluster topology also intersects with data sovereignty requirements: some regulatory frameworks mandate that certain categories of data remain within specific geographic boundaries, which requires the Kubernetes clusters processing that data to be deployed within those boundaries.
Workload type segmentation. AI and machine learning workloads running on GPU nodes, batch processing workloads with high resource consumption, and standard application workloads have different resource profiles and scheduling requirements. Separating them onto dedicated clusters prevents resource contention and allows each cluster type to be sized and configured for its specific workload profile.
Organizations will adopt new frameworks and control planes to unify management across thousands of distributed clusters, enabling low-latency processing, improved resilience, and compliance with local regulations.
The clusters in each category connect to the Tigera Partnership network security layer at the cluster level. Zero trust network policies that enforce compliance boundaries within a cluster complement the cluster-level isolation that the topology provides. A workload that should be isolated by running in a dedicated cluster and should be isolated by network policy within that cluster has defense in depth that neither control provides independently.
Fleet: GitOps-Based Multi-Cluster Configuration Management
Fleet, the GitOps tool built into Rancher, is what makes the multi-cluster topology described above operationally manageable rather than operationally overwhelming.
Without Fleet, a configuration change that applies to every production cluster requires a separate deployment operation on each cluster in the production group. With Fleet, the change is made once in the Git repository that Fleet watches, and Fleet propagates it to every cluster in the target group. The scope of "production clusters" is defined by a cluster label or group in Fleet's configuration. Adding a new production cluster to the group automatically makes it subject to the same configuration management as every other production cluster.
Fleet also supports rollout strategies that apply changes progressively across the fleet rather than simultaneously. A Kubernetes version upgrade that applies to 20 production clusters can be configured to apply to two clusters first, validate for 24 hours, apply to five more, validate again, and then complete the rollout across the remaining 13. This progressive rollout prevents a misconfiguration or incompatibility from affecting every cluster simultaneously, which is the specific risk that makes fleet-wide changes anxiety-inducing without a controlled rollout mechanism.
The GitOps integration extends to the GitLab Partnership delivery layer. GitLab CI/CD pipelines produce the application artifacts and Kubernetes manifests that Fleet deploys across the cluster fleet. The pipeline that builds, tests, and security-scans an application and the Fleet configuration that deploys it are two layers of the same delivery workflow. Changes that pass the GitLab pipeline validation are candidates for Fleet deployment. The delivery chain from code commit to fleet-wide deployment is auditable end to end.
Multi-Cluster Security: Consistency Is the Requirement
The security challenge of multi-cluster environments is not that any individual cluster is difficult to secure. It is that maintaining consistent security configuration across multiple clusters over time without a central enforcement mechanism is operationally impractical.
Security configuration that was identical across all clusters on the day they were provisioned diverges as each cluster evolves independently. An upgrade on one cluster changes a default configuration. A team adds a namespace on another cluster without following the standard isolation pattern. A third cluster gets an additional add-on that opens a port nobody documented. Over months, the security posture of individually managed clusters becomes a set of individual histories rather than a consistent organizational standard.
Enforcing consistent security posture, audit trails, and supply-chain guarantees across cloud and on-prem is hard, particularly when multiple vendor distributions and custom images are in play.
Rancher's centralized policy management prevents this drift by enforcing organization-wide security configuration from the management plane. Security policies that must apply to every cluster, such as the requirement for image scanning admission control, the prohibition on privileged containers, and the network isolation requirements for compliance boundaries, are configured in Rancher rather than on each individual cluster. A cluster that drifts from the policy is surfaced in the Rancher dashboard rather than being invisible until an audit discovers it.
The Tigera Partnership Calico Enterprise multi-cluster network security extends this consistency to the network policy layer. Zero trust network policies defined in Calico Enterprise propagate to every cluster in the fleet. A new cluster added to the fleet inherits the network security configuration of its cluster group rather than starting with the default-allow posture that vanilla Kubernetes clusters have from inception.
The Solo Consulting API gateway layer connects to the multi-cluster topology at the traffic management boundary. Gloo Mesh provides the unified service mesh management that makes mTLS enforcement and traffic management consistent across clusters, which is particularly important for applications where a user request might touch services running in different clusters.
The Cost of Multi-Cluster Management Done Right Versus Done Poorly
88% of teams report year-over-year TCO increases for Kubernetes. As clusters proliferate and workloads grow, TCO will attract greater scrutiny. Adoption of FinOps as part of cloud-native operations will gain more traction in 2026.
The TCO increase that most organizations experience in multi-cluster environments is predominantly operational overhead, not infrastructure cost. The infrastructure cost of running five clusters instead of one is roughly five times the infrastructure cost of one cluster, which scales linearly. The operational overhead of managing five individually configured clusters is not five times the overhead of one cluster. It is significantly higher because cross-cluster consistency, cross-cluster security, and cross-cluster upgrade management are harder problems than managing within one cluster.
Unified multi-cluster management with SUSE Rancher changes the operational cost model. The overhead per cluster drops because most cluster management operations become fleet-level operations rather than per-cluster operations. Provisioning a new cluster from a template takes minutes rather than days. Applying a security policy to all clusters requires one change in the management plane rather than 12 changes across 12 clusters. Auditing the security posture of the fleet requires one compliance report rather than 12 individual cluster audits.
The investment in the multi-cluster management platform does not eliminate operational overhead. It replaces a cost model that scales with cluster count with a cost model that scales with fleet complexity, which grows much more slowly than cluster count for well-governed environments.
FAQ
What is Kubernetes multi-cluster management and when does an organization need it?
Kubernetes multi-cluster management is the practice of operating and governing multiple Kubernetes clusters as a coherent fleet rather than as independent infrastructure. An organization needs it when a single cluster can no longer satisfy competing requirements simultaneously: compliance isolation that requires workloads to be physically separated, team autonomy requirements that create coordination overhead in shared environments, geographic distribution that requires infrastructure in multiple regions, or workload type separation that needs dedicated GPU or high-performance compute environments. 82% of organizations run Kubernetes in production in 2026, and multi-cluster management has become the operational baseline for enterprise-scale deployments.
Why do single-cluster architectures fail at enterprise scale?
Single-cluster architectures fail at enterprise scale when compliance isolation requirements mandate separate physical infrastructure, when team count grows to the point where shared cluster change management creates unacceptable coordination overhead, when geographic distribution requires clusters in multiple regions to satisfy latency requirements, or when AI and machine learning workloads need dedicated GPU infrastructure that cannot share resources with production application workloads. The failure is not a technical limitation of Kubernetes itself. It is the practical impossibility of having one cluster simultaneously satisfy requirements that are structurally incompatible with shared infrastructure.
What is SUSE Rancher Fleet and how does it help manage multiple Kubernetes clusters?
SUSE Rancher Fleet is the GitOps-based continuous delivery tool built into Rancher for managing workload deployment and configuration across multiple clusters simultaneously. It watches Git repositories for changes to Kubernetes configurations and propagates those changes to the clusters in each target group. A configuration update that would require 20 separate deployment operations across a 20-cluster fleet becomes one change in the Git repository that Fleet deploys everywhere. Fleet also supports progressive rollout strategies that apply changes to a subset of clusters first, validate the change, and continue the rollout only after validation succeeds, preventing fleet-wide disruption from misconfigured updates.
How do you maintain consistent security across multiple Kubernetes clusters?
Consistent security across multiple Kubernetes clusters requires a central enforcement mechanism rather than per-cluster configuration management. SUSE Rancher's centralized policy management enforces organization-wide security configuration from the management plane, ensuring clusters cannot drift from the standard without the drift being visible and correctable from a single interface. Calico Enterprise's multi-cluster network security extends this consistency to the network policy layer, propagating zero trust policies to every cluster in the fleet. Without a central enforcement mechanism, security configuration that was identical at cluster provisioning time diverges as each cluster evolves independently, which 88% of Kubernetes teams report contributes to year-over-year TCO increases.