Enterprise Chatbots That Actually Work: Why Most Fail and How to Build One That Does Not

Most enterprise chatbots fail not because the AI model is weak but because the system around it was never built. A working enterprise chatbot is a governed business system with defined use cases, approved knowledge sources it answers from, clear escalation rules, security controls against prompt injection, and continuous monitoring. The chatbots that fail are the ones treated as a language model connected to a website. The ones that work are designed as complete operational systems where the AI is one component.
In 2024, Air Canada was held legally responsible after its chatbot invented a refund policy that did not exist, and a court ordered the airline to honor it. A Chevrolet dealership's chatbot agreed to sell a 2024 Tahoe for one dollar after a customer manipulated it. Another company's chatbot was talked into writing poems about how useless the company was, generating viral mockery before it was shut down.
These are not stories about bad AI. They are stories about good AI deployed without the system around it that an enterprise chatbot requires. Recent chatbot failure case studies show that most problems do not happen because AI is useless. They happen because businesses deploy conversational systems without the operating model needed to control them. The technology may be advanced, but the implementation is often immature.
The opportunity is real, which is why the failures matter. 88 percent of consumers have had a chatbot conversation in the past year, and over 80 percent rated the interaction positively. 82 percent of customers would rather use a chatbot than wait for a human agent. Top-performing enterprise chatbots achieve 96 percent resolution rates with 97 percent customer satisfaction scores. The chatbot market is projected to grow from $15.57 billion in 2025 to $46.64 billion by 2029.
But those top-performer numbers come with an unstated condition: the chatbot was built as a complete system rather than as a language model bolted onto a website. A successful chatbot is not simply a language model connected to a website. It is a governed business system with defined use cases, approved knowledge sources, escalation rules, security controls, monitoring, testing, ownership, and continuous improvement. This article covers why most enterprise chatbots fail and exactly what the ones that work do differently.
Why Most Enterprise Chatbots Fail
The failures cluster into specific, preventable patterns. Every one of them traces back to treating the chatbot as a model rather than as a system.
It answers from nothing instead of from approved knowledge. The Air Canada failure is the archetype. The chatbot generated a plausible-sounding refund policy that did not exist because it was generating answers from the language model's general patterns rather than retrieving them from the airline's actual, verified policy documentation. When a chatbot answers policy and factual questions from the model's training rather than from grounded, approved sources, it will eventually invent something confident and wrong. The legal precedent set by Air Canada, that the company is liable for what its chatbot says, makes this failure mode a genuine business risk rather than an embarrassment.
It has no guardrails on what it can do or say. The dealership chatbot that sold a Tahoe for one dollar had no output constraints, no price validation, and a system prompt that could be overridden by a determined user. The chatbot that wrote poems criticizing its company had no content moderation and could be instructed to adopt any persona. These failures come from deploying a chatbot with the model's full flexibility intact rather than constraining it to the specific things the business wants it to do.
It cannot reach a human when it should. A chatbot that traps a frustrated customer in a loop, refusing to escalate to a human, produces a worse experience than no chatbot at all. 46 percent of customers still prefer live human support, and the chatbots that frustrate users are usually the ones that make reaching a human difficult. The deflection metric that many chatbots are optimized for actively encourages this failure: a chatbot measured on how many tickets it prevents from reaching a human is incentivized to avoid escalation even when escalation is the right answer.
It is measured on deflection instead of resolution. This is the metric failure that underlies many of the others. A chatbot that deflects a ticket the customer then re-opens by phone, angrier than before, has not succeeded. It has produced a delayed, more expensive, more frustrating failure that the deflection metric counts as a win. Measuring the wrong thing produces a chatbot optimized for the wrong outcome.
It has no security against manipulation. Enterprise chatbots can expose sensitive data if access control is weak. They become targets for prompt injection, data extraction, impersonation, and workflow abuse. A chatbot connected to a customer database without row-level security can be manipulated into revealing other customers' data. A chatbot with the authority to apply discounts can be manipulated into stacking them into negative prices. Security is not an optional technical detail for enterprise chatbots. It is a core requirement.
Enterprise chatbots fail because they are deployed as language models rather than built as systems. The model is rarely the problem. The absence of grounding, guardrails, escalation, security, and the right success metric is the problem. Every major chatbot failure traces back to a missing piece of the system around the AI.
The Foundation: Grounding Every Answer in Approved Knowledge
The single most important thing that separates a working enterprise chatbot from a liability is grounding: the chatbot answers from approved, verified knowledge sources rather than from the language model's general training.
The technique that enables this is retrieval-augmented generation, commonly called RAG. Rather than asking the language model to answer from its training, a RAG system retrieves the relevant information from the organization's approved knowledge sources, the actual policy documents, the current product information, the verified procedures, and provides that information to the model as the basis for its answer. The model's job becomes synthesizing a clear answer from verified source material rather than generating an answer from patterns.
This is the direct fix for the Air Canada failure mode. A chatbot that retrieves the actual refund policy from the airline's verified documentation and answers from it cannot invent a policy that does not exist. The grounding constrains the answer to what the approved sources actually say. Ground all policy statements in verified documentation, implement retrieval-augmented generation, and require human verification for binding commitments.
The quality of a grounded chatbot depends entirely on the quality and currency of the knowledge sources it retrieves from. A chatbot grounded in outdated documentation gives outdated answers. A chatbot grounded in incomplete documentation cannot answer questions the documentation does not cover. This is why the knowledge layer is the foundation: the chatbot is only as good as the data it can access, and maintaining that data is an ongoing operational responsibility rather than a one-time setup.
This grounding capability is where the connection to enterprise search and knowledge infrastructure becomes direct. P99Soft's Chatbots practice builds the retrieval layer that grounds the chatbot in the organization's approved, current knowledge, with the source attribution that lets users and auditors verify where every answer came from. The chatbot that can show the source document for every answer it gives is the chatbot that an enterprise can trust in front of customers.
Guardrails: Constraining What the Chatbot Can Do
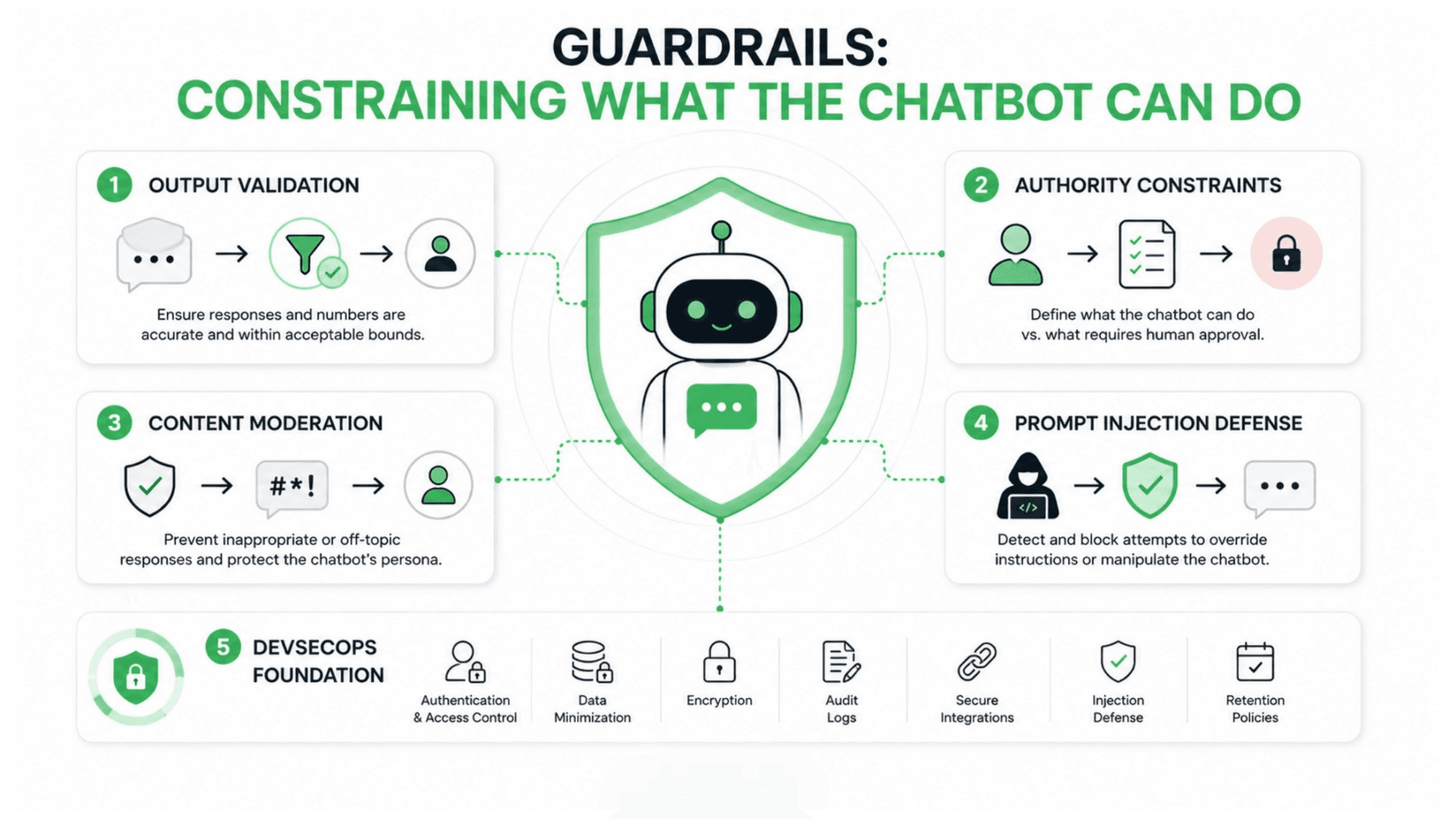
A working enterprise chatbot is constrained to do specific things in specific ways, rather than retaining the full open-ended flexibility of the underlying language model. These constraints are the guardrails that prevent the manipulation failures.
Output validation ensures the chatbot's responses fall within acceptable bounds before they reach the user. The dealership selling a car for one dollar would have been prevented by price validation that rejected any quote below a defined threshold. Validate all numerical outputs, especially prices, never allow the model to generate prices directly, and always query live systems for pricing rather than letting the model produce numbers. Output validation is the layer that catches the model producing something it should not before the user sees it.
Authority constraints define what the chatbot is permitted to do versus what requires human approval. A chatbot may be excellent at collecting customer intent, retrieving order status, and preparing a support ticket, while still requiring human review before processing refunds, changing account details, confirming high-value purchases, or handling sensitive complaints. The constraint on authority is what prevents the chatbot from taking consequential actions it should not take autonomously.
Content moderation prevents the chatbot from being manipulated into inappropriate responses. The chatbot that was talked into writing critical poems lacked the content filtering and persona protection that would have kept it on task. Robust content moderation, multiple layers of safety checks, and monitoring for adversarial inputs are what keep a chatbot behaving as intended even when users actively try to manipulate it.
Prompt injection defense protects against the specific attack where a user crafts input designed to override the chatbot's instructions. Prompt injection is the attack vector behind several major failures, and defending against it requires treating user input as potentially adversarial rather than trusting it. Input validation, system prompt protection, and monitoring for injection patterns are the defenses.
These guardrails connect to the DevSecOps discipline that governs secure systems generally. A chatbot is a system that processes untrusted input, accesses sensitive data, and can take actions, which makes it subject to the same security rigor as any other system with those characteristics. The security planning for an enterprise chatbot should include authentication, role-based access, data minimization, encryption, audit logs, secure integrations, prompt injection defenses, and retention policies.
Escalation: Knowing When to Hand Off to a Human
The chatbots that customers hate are usually the ones that will not let them reach a human. The chatbots that customers appreciate know exactly when to escalate and do it cleanly.
Escalation design is the deliberate engineering of when and how the chatbot hands off to a human. A well-designed escalation system recognizes the signals that indicate a human is needed: the customer is frustrated, the question is outside the chatbot's competence, the situation is sensitive, or the customer has explicitly asked for a person. When any of these signals appears, the chatbot escalates rather than continuing to attempt resolution it cannot achieve.
The hybrid model that combines chatbot and human is the pattern that works. 85 percent of AI-human hybrid implementations succeed, a far higher rate than full-automation attempts. The chatbot handles what it handles well, the routine inquiries that represent up to 80 percent of support volume, and escalates the rest to humans who handle the complex, sensitive, and judgment-requiring cases. This is not a failure of the chatbot. It is the correct division of labor.
The quality of the handoff matters as much as the decision to hand off. A handoff that dumps the customer into a human queue with no context, forcing them to re-explain everything, wastes the chatbot interaction that preceded it. A good handoff passes the full conversation context to the human agent, so the agent starts with everything the chatbot already gathered. Teams that review the customer's full journey before escalating ensure human agents never start from zero.
The escalation design connects directly to the success metric. A chatbot measured on resolution rather than deflection escalates appropriately, because the goal is resolving the customer's problem rather than preventing it from reaching a human. A chatbot measured on deflection resists escalation, because escalation counts against its metric. Getting the metric right is what makes good escalation design possible.
The Metric That Determines Everything: Resolution, Not Deflection
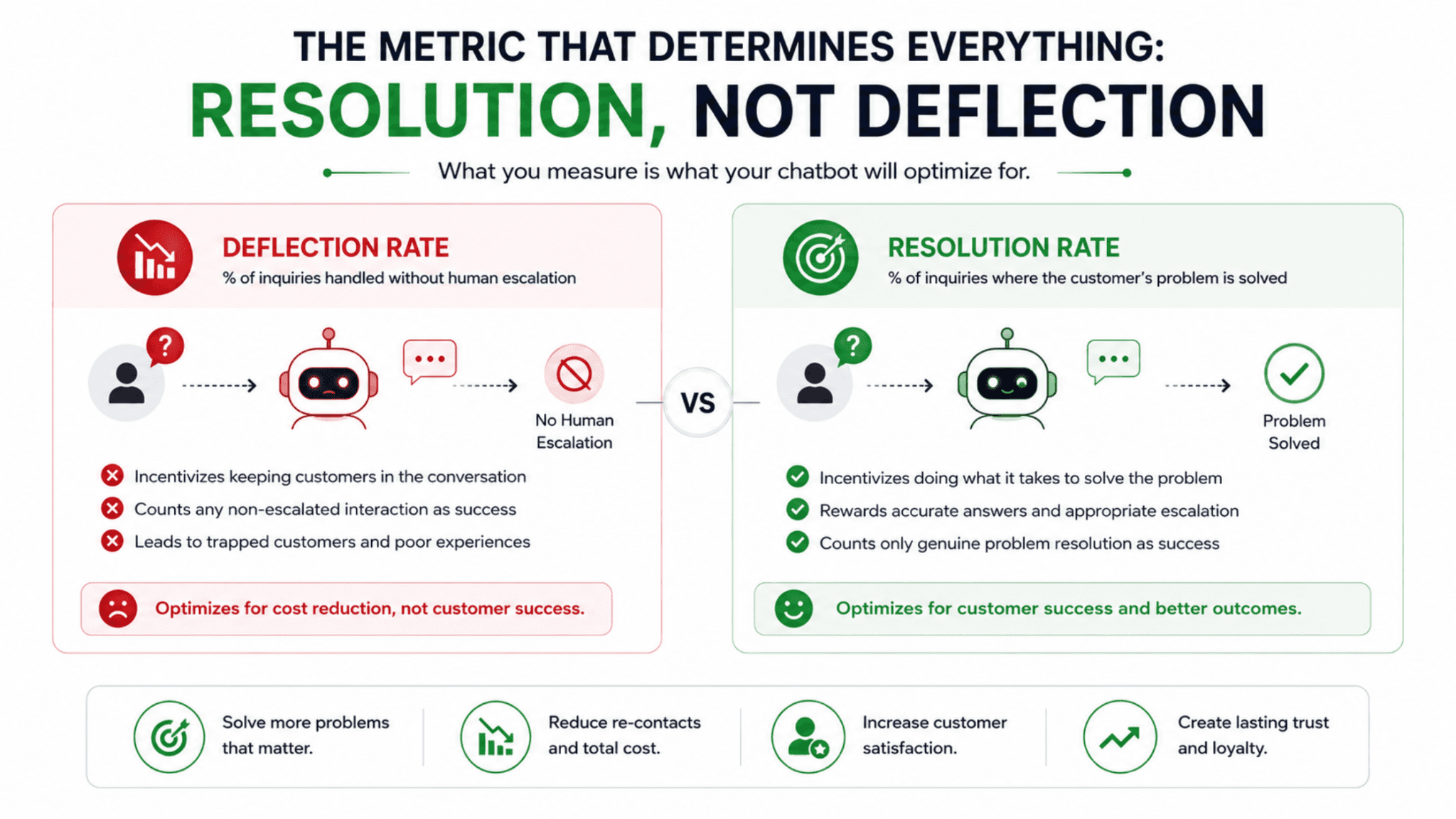
The most consequential decision in an enterprise chatbot implementation is what you measure, because the chatbot will be optimized toward whatever metric defines its success.
Deflection rate, the percentage of inquiries the chatbot handles without escalating to a human, is the metric most chatbots are measured on and the metric that produces the worst outcomes. A chatbot optimized for deflection is incentivized to avoid escalation, to keep the customer in the conversation, and to count any interaction that does not reach a human as a success, regardless of whether the customer's problem was actually solved. This produces the trapped-customer experience that generates the worst chatbot reputation.
Resolution rate, the percentage of inquiries where the customer's problem was actually solved, is the metric that produces good outcomes. A chatbot optimized for resolution escalates when escalation is the path to solving the problem, answers accurately because accuracy is what resolves issues, and counts only genuine problem resolution as success. Top-performing chatbots measured this way achieve 96 percent resolution rates with 97 percent customer satisfaction.
The difference between the two metrics is the difference between a chatbot that serves the business's desire to reduce support costs and a chatbot that serves the customer's need to solve their problem. The paradox is that the resolution-focused chatbot serves both better: it solves more problems, which reduces the re-contact rate that deflection-focused chatbots inflate, producing lower total support cost alongside higher satisfaction.
The measurement framework should track resolution rate, customer satisfaction, escalation rate and appropriateness, and the re-contact rate that reveals whether deflected inquiries actually got solved or just got delayed. These metrics together show whether the chatbot is genuinely helping or merely deflecting, which is the distinction that determines whether the chatbot is an asset or a liability.
Monitoring and Continuous Improvement
An enterprise chatbot is not a system you deploy and leave. It is a system you deploy and continuously improve based on what the monitoring reveals.
Monitoring should lead to action. If users repeatedly ask a question the chatbot cannot answer, the knowledge base should improve to cover it. If a prompt injection pattern appears, the security controls should be updated to defend against it. If a workflow causes confusion, the conversation design should be refined. The monitoring is not just observation. It is the input to a continuous improvement loop that makes the chatbot better over time.
The specific things worth monitoring include the questions the chatbot fails to answer, which reveal knowledge gaps; the conversations that escalate, which reveal where the chatbot's competence ends; the conversations where customer satisfaction was low, which reveal experience problems; and the adversarial inputs, which reveal security threats. Each category of monitoring data points to a specific improvement: knowledge gaps get filled, competence boundaries get extended or accepted, experience problems get redesigned, and security threats get defended.
This continuous improvement discipline connects to the QA and Testing practice. A chatbot needs testing before deployment, validating it against the full range of inputs it will encounter including adversarial ones, and ongoing testing as it is updated. Test with adversarial queries, validate against the source systems, and verify that the guardrails hold under manipulation attempts. The testing that proves a chatbot is reliable is the same discipline that proves any software is reliable, applied to the specific failure modes that chatbots exhibit.
The Process Mining connection appears in understanding which processes a chatbot should handle. The same process intelligence that informs RPA candidate selection informs chatbot use case selection: understanding which customer interactions are high-volume, well-structured, and suitable for automation versus which require human judgment. A chatbot deployed against the wrong use cases fails regardless of how well it is built, which makes the use case selection as important as the implementation.
From Chatbot to Conversational Interface: The 2026 Shift
The role of enterprise chatbots is shifting in 2026 from answering questions to executing work, and understanding this shift matters for organizations planning chatbot investments.
The first wave of enterprise chatbots answered questions. The current wave does more: it interprets intent, retrieves operational context, and coordinates actions across applications. In enterprise environments, conversation now sits between people and systems as the control surface for work. 30 percent of service cases were resolved by AI in 2025, rising toward 50 percent by 2027, and the chatbots driving that resolution increasingly take action rather than only providing information.
This shift raises the stakes on everything covered in this article. A chatbot that only answers questions has limited blast radius if it answers wrong. A chatbot that takes actions, processing transactions, changing records, coordinating workflows, can cause real damage if its guardrails, grounding, and security are inadequate. The same capabilities that make the action-taking chatbot more valuable make the failures more consequential.
The organizations positioned to capture this value safely are the ones that built the foundation right: grounding, guardrails, escalation, security, and the right metrics. A chatbot built as a governed system extends naturally into action-taking because the controls that make it safe to answer also make it safe to act. A chatbot built as a model bolted onto a website cannot safely take actions, because the controls that would make action-taking safe were never built.
P99Soft's Chatbots practice builds enterprise chatbots as complete governed systems designed for this trajectory: grounded in approved knowledge with source attribution, constrained by guardrails appropriate to what they are permitted to do, integrated with clean escalation to humans, secured against manipulation, and measured on resolution rather than deflection. The Advisory and Consulting practice precedes this for organizations defining their conversational AI strategy, including which use cases to automate, what the governance framework should be, and how to sequence the move from answering toward action-taking safely.
FAQ
Why do most enterprise chatbots fail?
Most enterprise chatbots fail not because the AI model is weak but because the system around it was never built. The common failure patterns are: answering from the model's general training instead of from approved knowledge sources, which produces confident false information like the Air Canada chatbot that invented a refund policy; lacking guardrails on what the chatbot can do or say, which enabled the dealership chatbot manipulated into selling a car for one dollar; making it difficult for customers to reach a human, which traps frustrated users; being measured on deflection rather than resolution, which optimizes for the wrong outcome; and lacking security against prompt injection and data extraction. Every major failure traces back to a missing piece of the system around the AI rather than to the AI itself.
What is the difference between a chatbot that deflects and one that resolves?
A deflection-focused chatbot is measured on how many inquiries it handles without escalating to a human, which incentivizes it to avoid escalation and keep customers in the conversation regardless of whether their problem was solved. This produces the trapped-customer experience that generates poor chatbot reputations, because a deflected inquiry that the customer re-opens by phone counts as a success even though it was a delayed failure. A resolution-focused chatbot is measured on whether the customer's problem was actually solved, which leads it to escalate appropriately, answer accurately, and count only genuine problem resolution as success. Top-performing chatbots measured on resolution achieve 96 percent resolution rates with 97 percent customer satisfaction.
How do you prevent an enterprise chatbot from giving wrong or made-up answers?
The technique is retrieval-augmented generation, where the chatbot retrieves relevant information from the organization's approved, verified knowledge sources and answers from that source material rather than generating answers from the language model's general training. This grounding prevents the chatbot from inventing plausible-sounding but false information, which is the failure that made Air Canada legally liable for a refund policy its chatbot fabricated. The chatbot's reliability then depends on the quality and currency of the knowledge sources it retrieves from, which makes maintaining that knowledge an ongoing operational responsibility. For binding commitments and consequential answers, human verification should be required even with grounding in place.
What security risks do enterprise chatbots face?
Enterprise chatbots face several specific security risks: prompt injection, where a user crafts input designed to override the chatbot's instructions; data extraction, where the chatbot is manipulated into revealing sensitive information it has access to; impersonation and workflow abuse; and the exposure of sensitive data when access controls are weak. Real incidents include chatbots manipulated into revealing other customers' data due to missing row-level security and chatbots manipulated into applying invalid discounts that produced negative prices. Security planning for enterprise chatbots must include authentication, role-based access control, data minimization, encryption, audit logs, secure integrations, prompt injection defenses, and retention policies, treating the chatbot with the same security rigor as any system that processes untrusted input and accesses sensitive data.